We have several scenarios which modifies input data. Iterations of such scenarios are not isolated between each other. Also, this patch returns NeutronNetworks.create_and_update_ports scenario from unstable to regular job. Change-Id: Ifa5d5ecd04507edb00e9befa1c7add075010258c |
||
|---|---|---|
| devstack | ||
| doc | ||
| etc | ||
| rally | ||
| rally-jobs | ||
| samples | ||
| tests | ||
| .coveragerc | ||
| .dockerignore | ||
| .gitignore | ||
| .gitreview | ||
| Dockerfile | ||
| LICENSE | ||
| README.rst | ||
| requirements.txt | ||
| setup.cfg | ||
| setup.py | ||
| test-requirements.txt | ||
| tox.ini | ||
Rally
What is Rally
Rally is a Benchmark-as-a-Service project for OpenStack.
Rally is intended to provide the community with a benchmarking tool that is capable of performing specific, complicated and reproducible test cases on real deployment scenarios.
If you are here, you are probably familiar with OpenStack and you also know that it's a really huge ecosystem of cooperative services. When something fails, performs slowly or doesn't scale, it's really hard to answer different questions on "what", "why" and "where" has happened. Another reason why you could be here is that you would like to build an OpenStack CI/CD system that will allow you to improve SLA, performance and stability of OpenStack continuously.
The OpenStack QA team mostly works on CI/CD that ensures that new patches don't break some specific single node installation of OpenStack. On the other hand it's clear that such CI/CD is only an indication and does not cover all cases (e.g. if a cloud works well on a single node installation it doesn't mean that it will continue to do so on a 1k servers installation under high load as well). Rally aims to fix this and help us to answer the question "How does OpenStack work at scale?". To make it possible, we are going to automate and unify all steps that are required for benchmarking OpenStack at scale: multi-node OS deployment, verification, benchmarking & profiling.
Rally workflow can be visualized by the following diagram:

Who Is Using Rally
Documentation
Rally documentation on ReadTheDocs is a perfect place to start learning about Rally. It provides you with an easy and illustrative guidance through this benchmarking tool. For example, check out the Rally step-by-step tutorial that explains, in a series of lessons, how to explore the power of Rally in benchmarking your OpenStack clouds.
Architecture
In terms of software architecture, Rally is built of 4 main components:
- Server Providers - provide servers (virtual servers), with ssh access, in one L3 network.
- Deploy Engines - deploy OpenStack cloud on servers that are presented by Server Providers
- Verification - component that runs tempest (or another specific set of tests) against a deployed cloud, collects results & presents them in human readable form.
- Benchmark engine - allows to write parameterized benchmark scenarios & run them against the cloud.
Use Cases
There are 3 major high level Rally Use Cases:
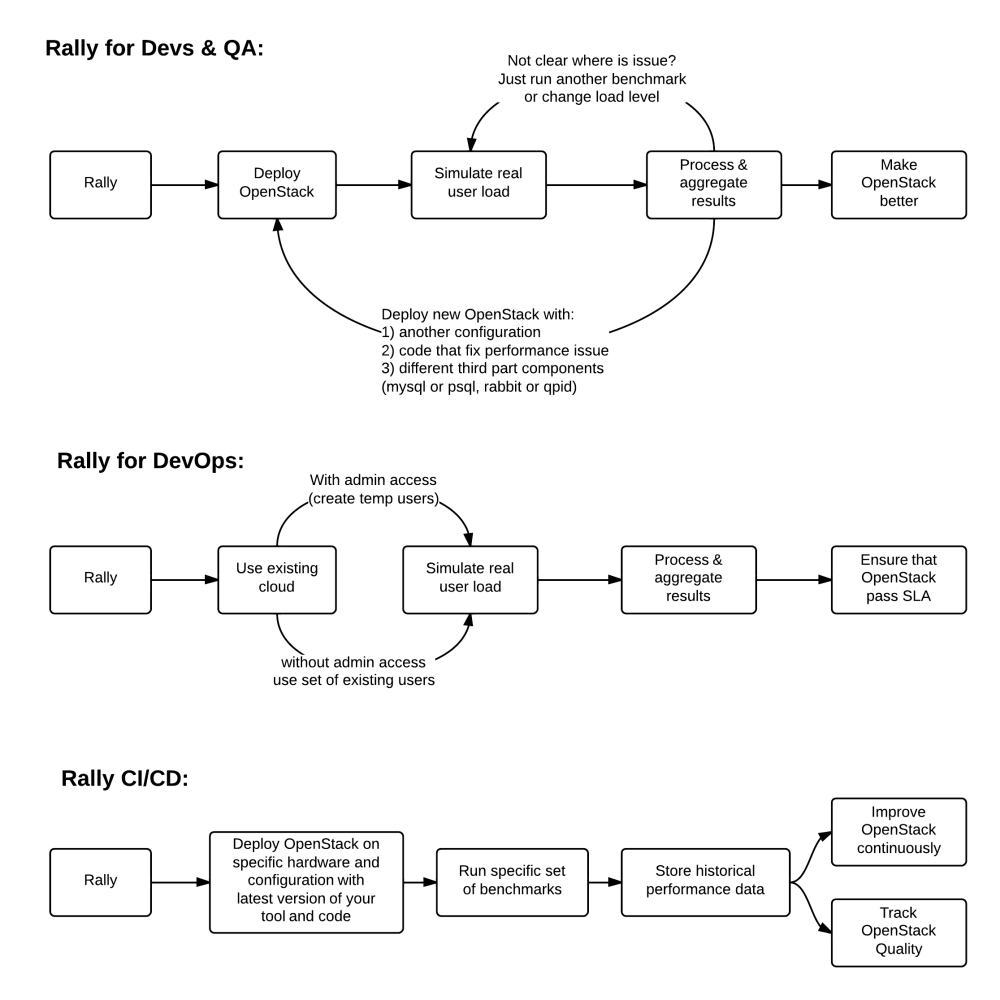
Typical cases where Rally aims to help are:
- Automate measuring & profiling focused on how new code changes affect the OS performance;
- Using Rally profiler to detect scaling & performance issues;
- Investigate how different deployments affect the OS performance:
-
- Find the set of suitable OpenStack deployment architectures;
- Create deployment specifications for different loads (amount of controllers, swift nodes, etc.);
- Automate the search for hardware best suited for particular OpenStack cloud;
- Automate the production cloud specification generation:
-
- Determine terminal loads for basic cloud operations: VM start & stop, Block Device create/destroy & various OpenStack API methods;
- Check performance of basic cloud operations in case of different loads.
Links
Rally documentation:
Rally step-by-step tutorial:
RoadMap:
https://docs.google.com/a/mirantis.com/spreadsheets/d/16DXpfbqvlzMFaqaXAcJsBzzpowb_XpymaK2aFY2gA2g
Launchpad page:
Code is hosted on git.openstack.org:
Code is mirrored on github: