2.4 KiB
NIC failure affects instances and applications
As a cloud operator, whenever one of my cloud's compute nodes has a NIC failure, I want to be notified of all affected resources including instances and applications. Moreover, I want the failed instances to be migrated away to another hardware so my applications will continue to function.
Problem description
A NIC failure may cause the host, as well as all instances running on it, to become unreachable. This may also affect applications that are using these instances and lose their high-availability.
Fault class
Network failure
OpenStack projects used
- Zabbix (or any other 3rd party monitor)
- Vitrage
- Mistral
Remediation class
Reactive
Fault detection
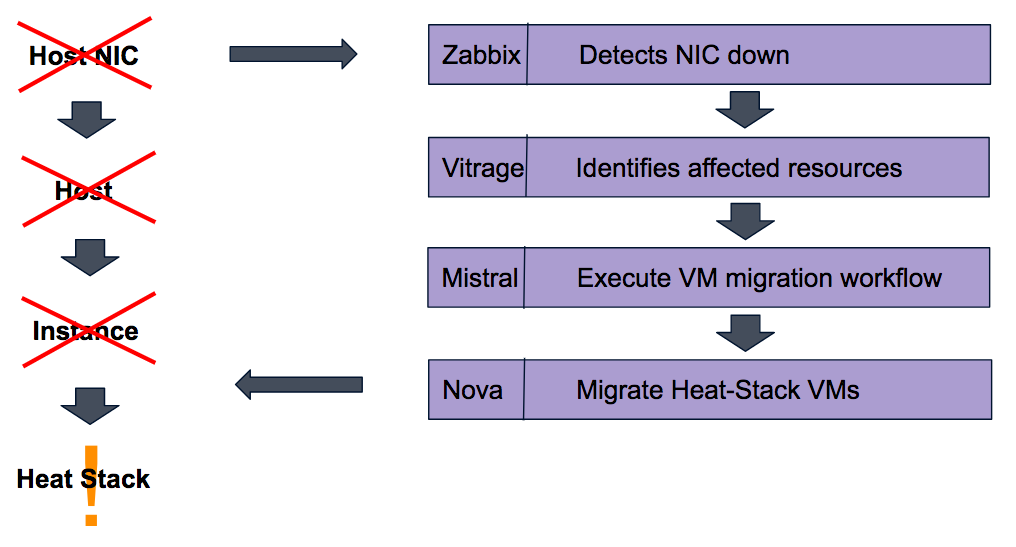
There is no OpenStack component that detects a NIC failure, so it has to be done using a 3rd party monitor like Zabbix.
Inputs and decision-making
Based on the NIC failure detection, the cloud operator should understand which resources and applications are affected.
Remediation
Instances that became unreachable due the the network failure should be migrated to another host, so the applications should continue to function.
Existing implementation(s)
To identify the failed resources, the cloud operator can use Vitrage. Vitrage will be notified by the external monitor (such as Zabbix) about the failed NIC. Based on its cloud topology awareness, Vitrage will raise additional alarms on the host, instances and affected applications.
An affected application will most likely be running in HA mode, so it will perform a fail-over to the standby instance. However, it will lose its high-availability.
The cloud operator can see this information in Vitrage Entity Graph, locate a failed instance that affects an application, and ask to execute a VM-migration Mistral workflow on that instance.
Alternatively, Vitrage can automatically execute a Mistral workflow that will migrate the failed instance to a different host, so the application will get back to a fully-operational state.
Future work
None (supported from OpenStack Queens and on)
Dependencies
None