Currently, freezer support using s3 driver. So this patch add s3 support in README.rst Change-Id: Ied902e7cca12e46689fc97fabd8452dae8166e87 |
||
|---|---|---|
| config-generator | ||
| devstack | ||
| doc | ||
| etc | ||
| freezer | ||
| install-guide/source | ||
| releasenotes | ||
| specs | ||
| .coveragerc | ||
| .gitignore | ||
| .gitreview | ||
| .pylintrc | ||
| .testr.conf | ||
| bindep.txt | ||
| CREDITS.rst | ||
| FAQ.rst | ||
| freezer_logo.jpg | ||
| HACKING.rst | ||
| INSTALL.rst | ||
| LICENSE | ||
| README.rst | ||
| requirements.txt | ||
| setup.cfg | ||
| setup.py | ||
| test-requirements.txt | ||
| TODO.rst | ||
| tox.ini | ||
{kind=link}
Team and repository tags

Freezer
![]()
NOTE
Freezer has four different components; Freezer Web UI, Freezer Scheduler, Freezer Agent and Freezer API.
If you need to use Freezer Backup Restore DR as a Service platform, you need to install Freezer Scheduler, Freezer Agent on client and Freezer Web UI, Freezer API on OpenStack controller server. (The server where your Horizon and Keystone installed)
This is the source code of Freezer Scheduler and Freezer Agent.
If you need to get the source code of other components, please visit proper Github pages:
Freezer Web UI: https://github.com/openstack/freezer-web-ui
Freezer API: https://github.com/openstack/freezer-api
Features
Freezer is a Backup Restore DR as a Service platform that helps you to automate the data backup and restore process.
The following features are available:
- Backup file system using point-in-time snapshot
- Strong encryption supported: AES-256-CFB
- Backup file system tree directly (without volume snapshot)
- Backup journalled MongoDB directory tree using lvm snapshot to Swift
- Backup MySQL with lvm snapshot
- Restore data from a specific date automatically to file system
- Low storage consumption as the backup are uploaded as a stream
- Flexible backup policy (incremental and differential)
- Data is archived in GNU Tar format for file based incremental
- Multiple compression algorithm support (zlib, bzip2, xz)
- Remove old backup automatically according to the provided parameters
- Multiple storage media support (Swift, local file system, or ssh)
- Flush kernel buffered memory to disk
- Multi-platform (Linux, Windows, *BSD, OSX)
- Manage multiple jobs (I.e., multiple backups on the same node)
- Synchronize backups and restore on multiple nodes
- Web user interface integrated with OpenStack Horizon
- Execute scripts/commands before or after a job execution
Freezer Components
| Component | Description |
|---|---|
| Freezer Web UI | Web interface that interacts with the Freezer API to configure and change settings. It provides most of the features from the Freezer Agent CLI, advanced scheduler settings such as multi-node backup synchronization, metrics, and reporting. |
| Freezer Scheduler | A client side component, running on the node where the data backup is to be executed. It consists of a daemon that retrieves the data from the freezer API and executes jobs (i.e. backups, restore, admin actions, info actions, pre and/or post job scripts) by running the Freezer Agent. The metrics and exit codes returned by the freezer agent are captured and sent to the Freezer API. The scheduler manages the execution and synchronization of multiple jobs executed on a single or multiple nodes. The status of the execution of all the nodes is saved through the API. The Freezer scheduler takes care of uploading jobs to the API by reading job files on the file system. It also has its own configuration file where job session or other settings like the freezer API polling interval can be configured. The Freezer scheduler manages jobs, for more information about jobs please refer to: freezer_api/README.rst under JOB the sections |
| Freezer Agent | Multiprocessing Python software that runs on the client side, where the data backup is to be executed. It can be executed standalone or by the Freezer Scheduler. The Freezer Agent provides a flexible way to execute backup, restore and other actions on a running system. In order to provide flexibility in terms of data integrity, speed, performance, resources usage, etc the freezer agent offers a wide range of options to execute optimized backup according to the available resources as:
|
| Freezer API | The API is used to store and provide metadata to the Freezer Web UI and to the Freezer Scheduler. Also the API is used to store session information for multi node backup synchronization. No workload data is stored in the API. For more information to the API please refer to: freezer_api/README.rst |
| DB Elasticsearch | Backend used by the API to store and retrieve metrics, metadata sessions information, job status, etc. |
Linux Requirements
- OpenStack Swift Account (optional)
- python
- GNU Tar >= 1.26
- gzip, bzip2, xz
- OpenSSL
- python-swiftclient
- keystoneauth1
- pymongo
- PyMySQL
- libmysqlclient-dev
- sync
- libffi-dev
- libssl-dev
- python-dev
- pycrypto
- At least 128 MB of memory reserved for Freezer
Windows Requirements
- Python 2.7
- GNU Tar binaries (we recommend to follow [this guide] (https://github.com/openstack-freezer-utils/freezer-windows-binaries#windows-binaries-for-freezer) to install them)
- [OpenSSL pre-compiled for windows] (https://wiki.openssl.org/index.php/Binaries) or [direct download](https://indy.fulgan.com/SSL/openssl-1.0.1-i386-win32.zip)
- [Sync] (https://technet.microsoft.com/en-us/sysinternals/bb897438.aspx)
- [Microsoft Visual C++ Compiler for Python 2.7] (https://aka.ms/vcpython27)
- [PyWin32 for python 2.7] (https://sourceforge.net/projects/pywin32/files/pywin32/Build%20219/)
Add binaries to Windows Path
Go to Control PanelSystem and SecuritySystem and then Advanced System Settings, and click Environment Variables under System Variables edit Path and append in the end. - ;C:\Sync - ;C:\OpenSSL-Win64\bin - ;C:\Python27;C:\Python27\Lib\site-packages\;C:\Python27\Scripts\
The following components support Windows OS Platform:
- freezer-agent
- freezer-scheduler
Install Windows Scheduler
Freezer scheduler on windows run as a windows service and it needs to be installed as a user service.
- open cmd as admin
- whoami
- cd C:\Python27\Lib\site-packages\freezer\scheduler
- python win_service.py --username {whoami} --password {pc-password} install
Unofficial Installer for Windows
Freezer offers a [windows installer] (https://github.com/openstack-freezer-utils/freezer-windows-installer#windows-freezer-installer) supported by the community
Installation & Env Setup
Before Installation
1-) Chose correct branch for corresponding OpenStack version. If your OpenStack installation is Kilo, chose Stable/Kilo release. etc...
2-) This installation instruction only for Freezer Agent and Freezer Scheduler on client side. If you need to install other components, visit their Github page.
3-) Make sure you have installed same version of all four components. Do not miss match different version. For example; do not use Freezer Agent Stable/Kilo release with Freeze API Stable/Liberty release.
4-) Following installation instructions only for Freezer Scheduler and Freezer Agent.
Ubuntu / Debian
Swift client and Keystone client:
$ sudo apt-get install python-dev
For python3:
$ sudo apt-get install python3-dev
$ sudo easy_install -U pipMongoDB backup:
$ sudo apt-get install python-pymongoMySQL backup:
$ sudo pip install pymysqlFreezer installation from Python package repo:
$ sudo pip install freezerOR:
$ sudo easy_install freezerThe basic Swift account configuration is needed to use freezer. Make sure python-swiftclient is installed.
Also the following ENV vars are needed. You can put them in ~/.bashrc:
export OS_REGION_NAME=region-a.geo-1
export OS_TENANT_ID=<account tenant>
export OS_PASSWORD=<account password>
export OS_AUTH_URL=https://region-a.geo-1.identity.hpcloudsvc.com:35357/v2.0
export OS_USERNAME=automationbackup
export OS_TENANT_NAME=automationbackup
$ source ~/.bashrcLet's say you have a container called freezer_foobar-container, by executing "swift list" you should see something like:
$ swift list
freezer_foobar-container-2
$These are just use case example using Swift in the HP Cloud.
Is strongly advised to execute backups using LVM snapshot, so freezer will execute a backup on point-in-time data. This avoids the risk of data inconsistencies and corruption.
Windows
General packages:
> easy_install -U pip
> pip install freezerThe basic Swift account configuration is needed to use freezer. Make sure python-swiftclient is installed:
set OS_REGION_NAME=region-a.geo-1
set OS_TENANT_ID=<account tenant>
set OS_PASSWORD=<account password>
set OS_AUTH_URL=https://region-a.geo-1.identity.hpcloudsvc.com:35357/v2.0
set OS_USERNAME=automationbackup
set OS_TENANT_NAME=automationbackupUsage Example
Freezer will automatically add the prefix "freezer_" to the container name, where it is provided by the user and doesn't already start with this prefix. If no container name is provided, the default is "freezer_backups".
The execution options can be set from the command line and/or config file in ini format. There's an example of the job config file available in freezer/freezer/specs/job-backup.conf.example. Command line options always override the same options in the config file.
Backup
The most simple backup execution is a direct file system backup:
$ sudo freezer-agent --path-to-backup /data/dir/to/backup
--container freezer_new-data-backup --backup-name my-backup-name
* On windows (need admin rights)*
> freezer-agent --action backup --mode fs --backup-name testwindows
--path-to-backup "C:\path\to\backup" --container freezer_windows
--log-file C:\path\to\log\freezer.logBy default --mode fs is set. The command will generate a compressed tar gzip file of the directory /data/dir/to/backup. The generated file will be segmented in stream and uploaded in the Swift container called freezer_new-data-backup, with backup name my-backup-name.
Now check to see if your backup executed correctly by looking at /var/log/freezer.log
Execute a MongoDB backup using lvm snapshot:
We need to check before to see on which volume group and logical volume our mongo data is located. This information can be obtained as per the following:
$ mount
[...]Once we know the volume on which our Mongo data is mounted, we can get the volume group and logical volume info:
$ sudo vgdisplay
[...]
$ sudo lvdisplay
[...]We assume our mongo volume is "/dev/mongo/mongolv" and the volume group is "mongo":
$ sudo freezer-agent --lvm-srcvol /dev/mongo/mongolv --lvm-dirmount /var/lib/snapshot-backup
--lvm-volgroup mongo --path-to-backup /var/lib/snapshot-backup/mongod_ops2
--container freezer_mongodb-backup-prod --exclude "*.lock" --mode mongo --backup-name mongod-ops2Now freezer-agent creates an lvm snapshot of the volume /dev/mongo/mongolv. If no options are provided, the default snapshot name is "freezer_backup_snap". The snapshot vol will be mounted automatically on /var/lib/snapshot-backup, and the backup metadata and segments will be uploaded in the container mongodb-backup-prod with the name mongod-ops2.
Execute a file system backup using lvm snapshot:
$ sudo freezer-agent --lvm-srcvol /dev/jenkins/jenkins-home --lvm-dirmount
/var/snapshot-backup --lvm-volgroup jenkins
--path-to-backup /var/snapshot-backup --container freezer_jenkins-backup-prod
--exclude "\*.lock" --mode fs --backup-name jenkins-ops2MySQL backup requires a basic configuration file. The following is an example of the config:
$ sudo cat /root/.freezer/db.conf
[default]
host = your.mysql.host.ip
user = backup
password = userpasswordEvery listed option is mandatory. There's no need to stop the mysql service before the backup execution.
Execute a MySQL backup using lvm snapshot:
$ sudo freezer-agent --lvm-srcvol /dev/mysqlvg/mysqlvol
--lvm-dirmount /var/snapshot-backup
--lvm-volgroup mysqlvg --path-to-backup /var/snapshot-backup
--mysql-conf /root/.freezer/freezer-mysql.conf--container
freezer_mysql-backup-prod --mode mysql --backup-name mysql-ops002Cinder backups
To make a cinder backup you should provide cinder-vol-id or cindernative-vol-id parameters in command line arguments. Freezer doesn't do any additional checks and assumes that making a backup of that image will be sufficient to restore your data in the future.
Execute a cinder backup:
$ freezer-agent --mode cinder --cinder-vol-id 3ad7a62f-217a-48cd-a861-43ec0a04a78bExecute a MySQL backup with Cinder:
$ freezer-agent --mysql-conf /root/.freezer/freezer-mysql.conf
--container freezer_mysql-backup-prod --mode mysql
--backup-name mysql-ops002
--cinder-vol-id 3ad7a62f-217a-48cd-a861-43ec0a04a78bNova backups
To make a Nova backup you should provide a Nova parameter in the arguments. Freezer doesn't do any additional checks and assumes that making a backup of that instance will be sufficient to restore your data in future.
Execute a nova backup:
$ freezer-agent --mode nova --nova-inst-id 3ad7a62f-217a-48cd-a861-43ec0a04a78bExecute a MySQL backup with Nova:
$ freezer-agent --mysql-conf /root/.freezer/freezer-mysql.conf
--container freezer_mysql-backup-prod --mode mysql
--backup-name mysql-ops002
--nova-inst-id 3ad7a62f-217a-48cd-a861-43ec0a04a78bAll the freezer-agent activities are logged into /var/log/freezer.log.
Local, Swift, S3 compatible and SSH Storage
Freezer can use:
- local storage - a folder that is available in the same OS (may be mounted)
- Swift storage - OS object storage
- SSH storage - a folder on a remote machine
Local Storage
To use local storage specify "--storage local" And use "--container <path-to-folder-with-backups>" Backup example:
$ sudo freezer-agent --path-to-backup /data/dir/to/backup
--container /tmp/my_backup_path/ --backup-name my-backup-name
--storage localRestore example:
$ sudo freezer-agent --action restore --restore-abs-path /data/dir/to/backup
--container /tmp/my_backup_path/ --backup-name my-backup-name
--storage localSwift storage
To use swift storage specify "--storage swift" or omit "--storage" parameter altogether (Swift storage is the default). And use "--container <swift-container-name>"
Backup example:
$ sudo freezer-agent --path-to-backup /data/dir/to/backup
--container freezer-container --backup-name my-backup-name
--storage swiftRestore example:
$ sudo freezer-agent --action restore --restore-abs-path /data/dir/to/backup
--container freezer-container --backup-name my-backup-name
--storage swiftS3 compatible storage
To use S3 compatible storage specify "--storage s3" And use "--container <s3-bucket-name>" Also you should specify endpoint, access-key and secret-key parameters.
endpoint is the endpoint of S3 compatible storage access-key is the access key for S3 compatible storage secret-key is the secret key for S3 compatible storage
The basic S3 compatible storage account configuration is needed to using 's3' storage driver.
Make sure botocore is installed:
set ACCESS_KEY=<access-key>
set SECRET_KEY=<secret-key>
set ENDPOINT=<endpoint>Backup example:
$ sudo freezer-agent --path-to-backup /data/dir/to/backup
--container freezer-container --backup-name my-backup-name
--storage s3Restore example:
$ sudo freezer-agent --action restore --restore-abs-path /data/dir/to/backup
--container freezer-container --backup-name my-backup-name
--storage s3SSH storage
To use ssh storage specify "--storage ssh" And use "--container <path-to-folder-with-backups-on-remote-machine>" Also you should specify ssh-username, ssh-key and ssh-host parameters. ssh-port is optional parameter, default is 22.
ssh-username for user ubuntu should be "--ssh-username ubuntu" ssh-key should be path to your secret ssh key "--ssh-key <path-to-secret-key>" ssh-host can be ip of remote machine or resolvable dns name "--ssh-host 8.8.8.8"
Backup example:
$ sudo freezer-agent --path-to-backup /data/dir/to/backup
--container /remote-machine-path/ --backup-name my-backup-name
--storage ssh --ssh-username ubuntu --ssh-key ~/.ssh/id_rsa
--ssh-host 8.8.8.8Restore example:
$ sudo freezer-agent --action restore --restore-abs-pat /data/dir/to/backup
--container /remote-machine-path/ --backup-name my-backup-name
--storage ssh --ssh-username ubuntu --ssh-key ~/.ssh/id_rsa
--ssh-host 8.8.8.8Restore
As a general rule, when you execute a restore, the application that writes or reads data should be stopped so that during the restore operation, the restored data is not inadvertently read or written by the application.
There are 3 main options that need to be set for data restore
file system Restore:
Execute a file system restore of the backup name adminui.git:
$ sudo freezer-agent --action restore --container freezer_foobar-container-2
--backup-name adminui.git
--hostname git-HP-DL380-host-001 --restore-abs-path
/home/git/repositories/adminui.git/
--restore-from-date "2014-05-23T23:23:23"MySQL restore:
Execute a MySQL restore of the backup name holly-mysql. Let's stop mysql service first:
$ sudo service mysql stopExecute Restore:
$ sudo freezer-agent --action restore --container freezer_foobar-container-2
--backup-name mysq-prod --hostname db-HP-DL380-host-001
--restore-abs-path /var/lib/mysql --restore-from-date "2014-05-23T23:23:23"And finally restart mysql:
$ sudo service mysql startExecute a MongoDB restore of the backup name mongobigdata:
$ sudo freezer-agent --action restore --container freezer_foobar-container-2
--backup-name mongobigdata --hostname db-HP-DL380-host-001
--restore-abs-path /var/lib/mongo --restore-from-date "2014-05-23T23:23:23"List remote containers:
$ sudo freezer-agent --action infoList remote objects in container:
$ sudo freezer-agent --action info --container freezer_testcontainer -lRemove backups older then 1 day:
$ freezer-agent --action admin --container freezer_dev-test --remove-older-than 1 --backup-name dev-test-01Cinder restore currently creates a volume with the contents of the saved one, but doesn't implement detachment of existing volume and attachment of the new one to the vm. You should implement these steps manually. To create a new volume from existing content run the next command:
Execute a cinder restore:
$ freezer-agent --action restore --cinder-vol-id 3ad7a62f-217a-48cd-a861-43ec0a04a78b
$ freezer-agent --action restore --cindernative-vol-id 3ad7a62f-217a-48cd-a861-43ec0a04a78bNova restore currently creates an instance with the content of saved one, but the ip address of the vm will be different as well as its id.
Execute a nova restore:
$ freezer-agent --action restore --nova-inst-id 3ad7a62f-217a-48cd-a861-43ec0a04a78bLocal storage restore execution:
$ sudo freezer-agent --action restore --container /local_backup_storage/
--backup-name adminui.git
--hostname git-HP-DL380-host-001 --restore-abs-path
/home/git/repositories/adminui.git/
--restore-from-date "2014-05-23T23:23:23"
--storage localArchitecture
Freezer architectural components are the following:
- OpenStack Swift (the storage)
- freezer client running on the node where the backups and restores are to be executed
Freezer uses GNU Tar or Rsync algorithm under the hood to execute incremental backup and restore. When a key is provided, it uses OpenSSL or pycrypto module (OpenSSL compatible) to encrypt data. (AES-256-CFB)
The Freezer architecture is composed of the following components:
| Component | Description |
|---|---|
| Freezer Web UI | Web interface that interacts with the Freezer API to configure and change settings. It provides most of the features from the freezer-agent CLI as well as advanced scheduler settings such as multi-node backup synchronization, metrics, and reporting. |
| Freezer Scheduler | A client side component, running on the node where the data backup is to be executed. It consists of a daemon that retrieves the data from the freezer API and executes jobs (i.e., backups, restore, admin actions, info actions, pre and/or post job scripts) by running the Freezer Agent. The metrics and exit codes returned by the freezer agent are captured and sent to the Freezer API. The scheduler manages the execution and synchronization of multiple jobs executed on a single or multiple nodes. The status of the execution of all the nodes is saved through the API. The Freezer scheduler takes care of uploading jobs to the API by reading job files on the file system. It also has its own configuration file where job session or other settings like the freezer API polling interval can be configured. The Freezer scheduler manages jobs. For more information about jobs please refer to: freezer_api/README.rst under JOB the sections |
| Freezer Agent | Multiprocessing Python software that runs on the client side, where the data backup is to be executed. It can be executed standalone or by the Freezer Scheduler. The freezer-agent provides a flexible way to execute backup, restore and other actions on a running system. In order to provide flexibility in terms of data integrity, speed, performance, resources usage, etc the freezer agent offers a wide range of options to execute optimized backup according to the available resources as:
|
| Freezer API | The API is used to store and provide metadata to the Freezer Web UI and to the Freezer Scheduler. Also the API is used to store session information for multi node backup synchronization. No workload data is stored in the API. For more information on the API please refer to: freezer_api/README.rst |
| DB ElasticSearch | Backend used by the API to store and retrieve metrics, metadata sessions information, job status, etc. |
Freezer currently uses GNU Tar under the hood to execute incremental backup and restore. When a key is provided, it uses OpenSSL to encrypt data (AES-256-CFB).
The following diagrams can help to better understand the solution:
Service Architecture

Freezer Agent backup work flow with API
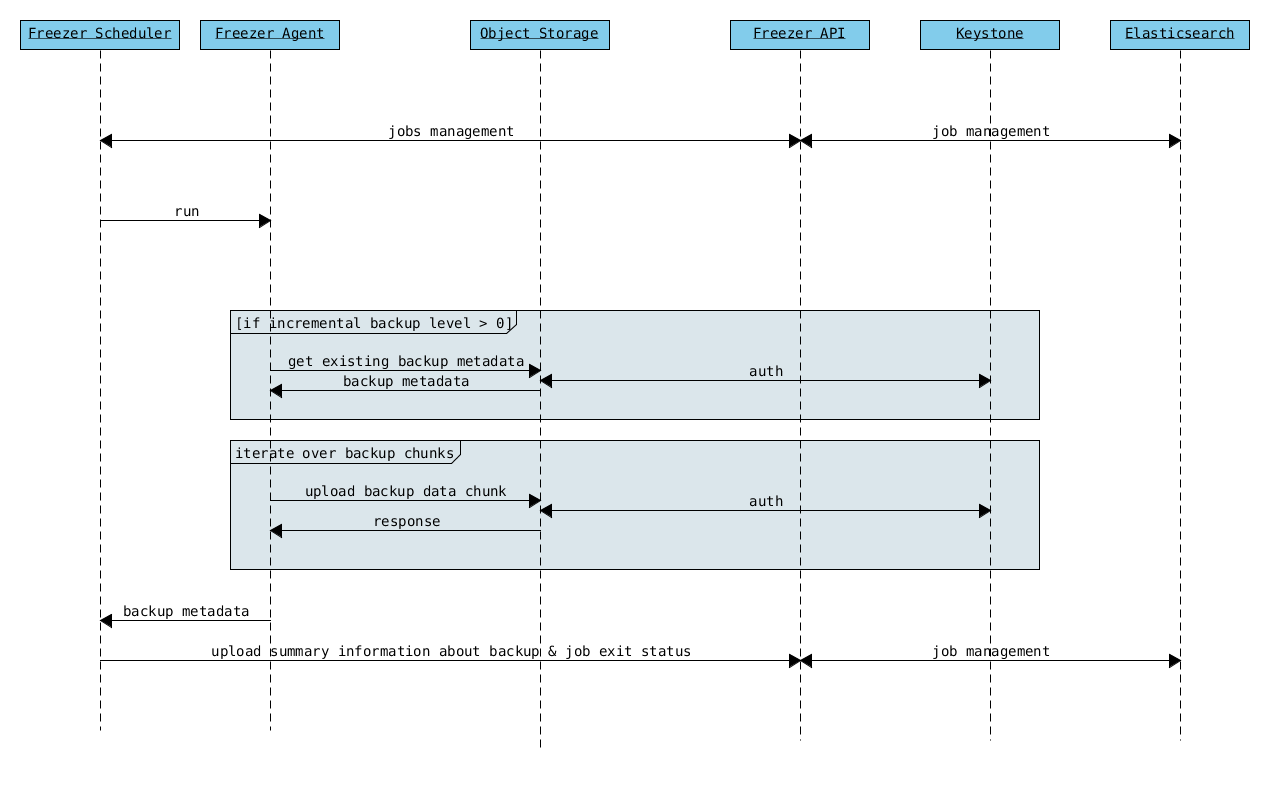
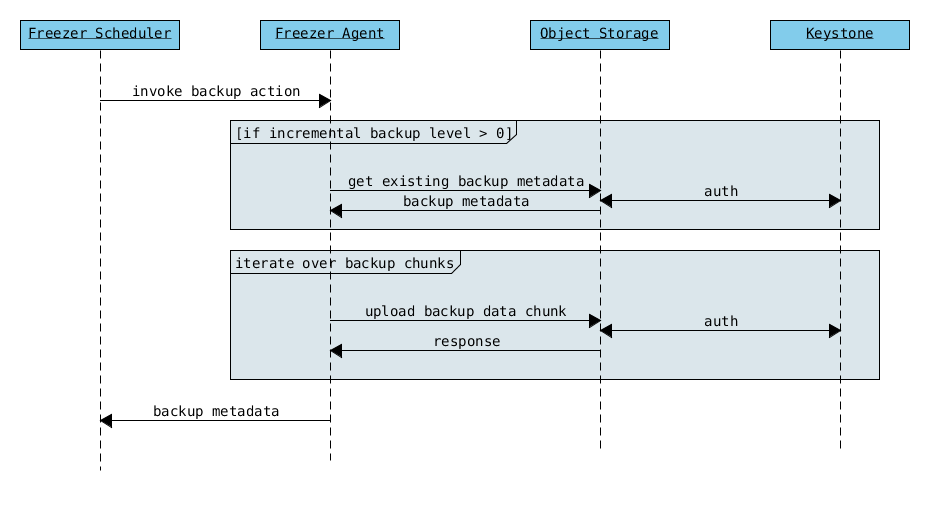
Freezer Agent backup without API
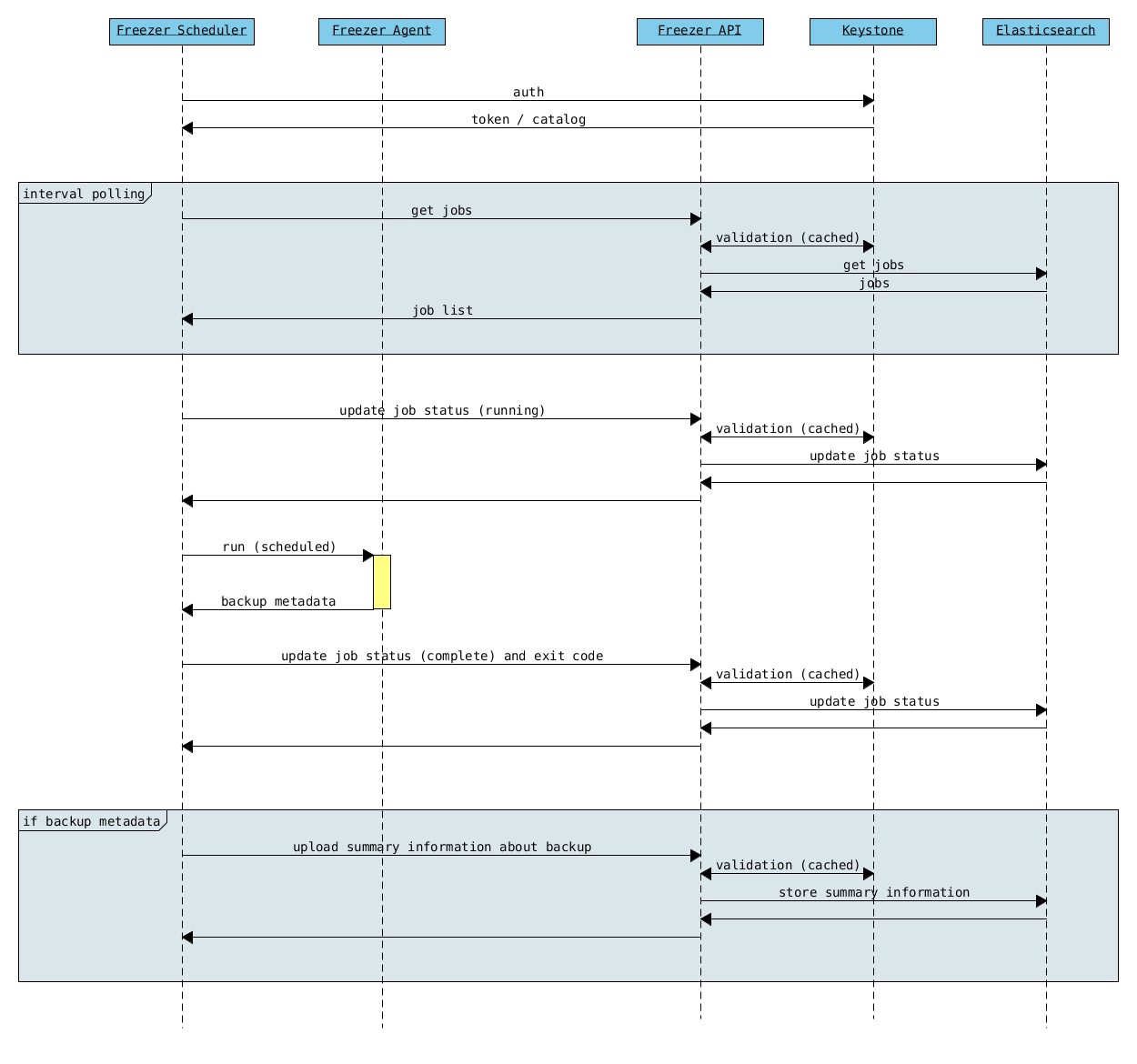
Freezer Scheduler with API
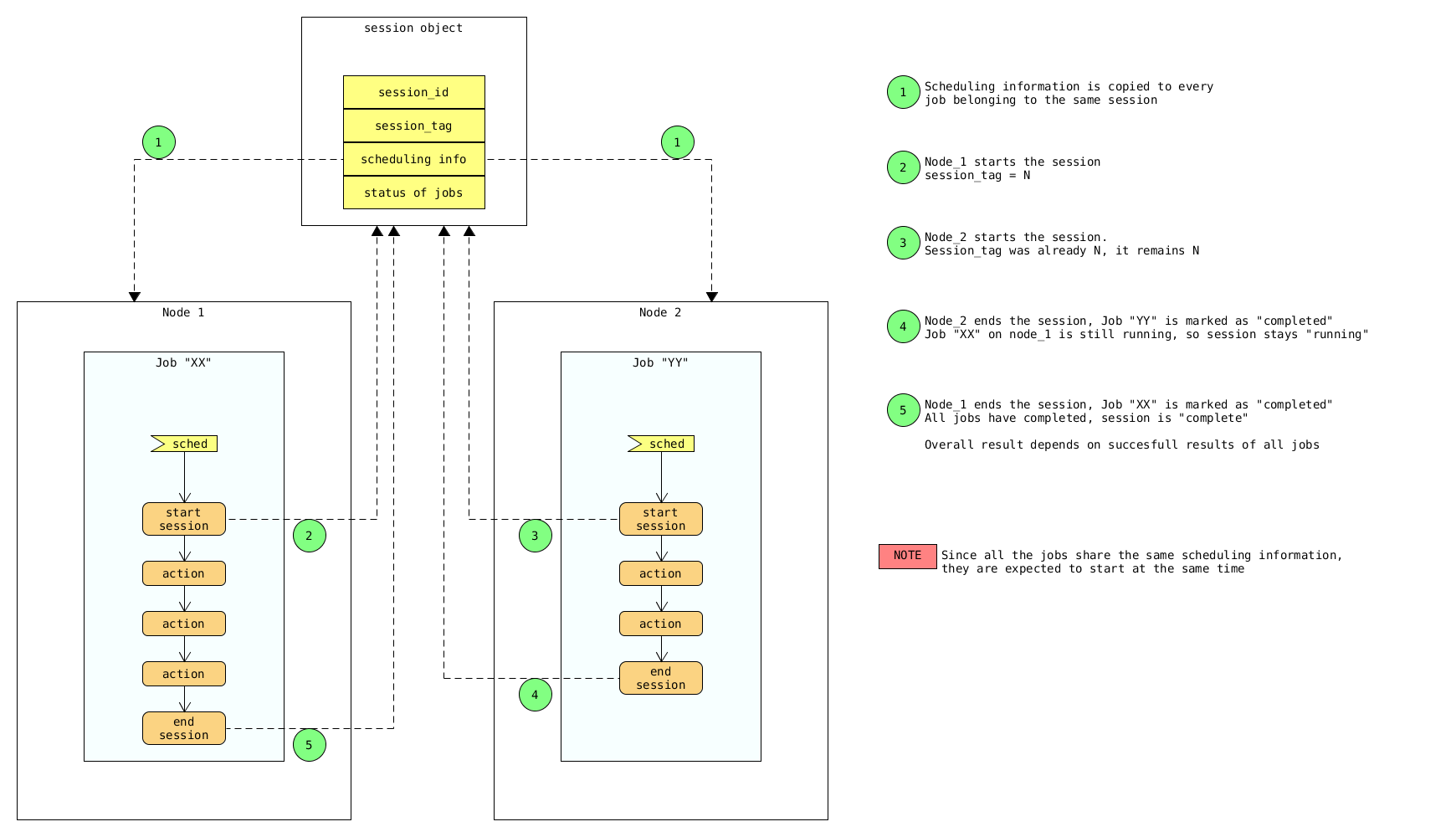
Freezer Job Session
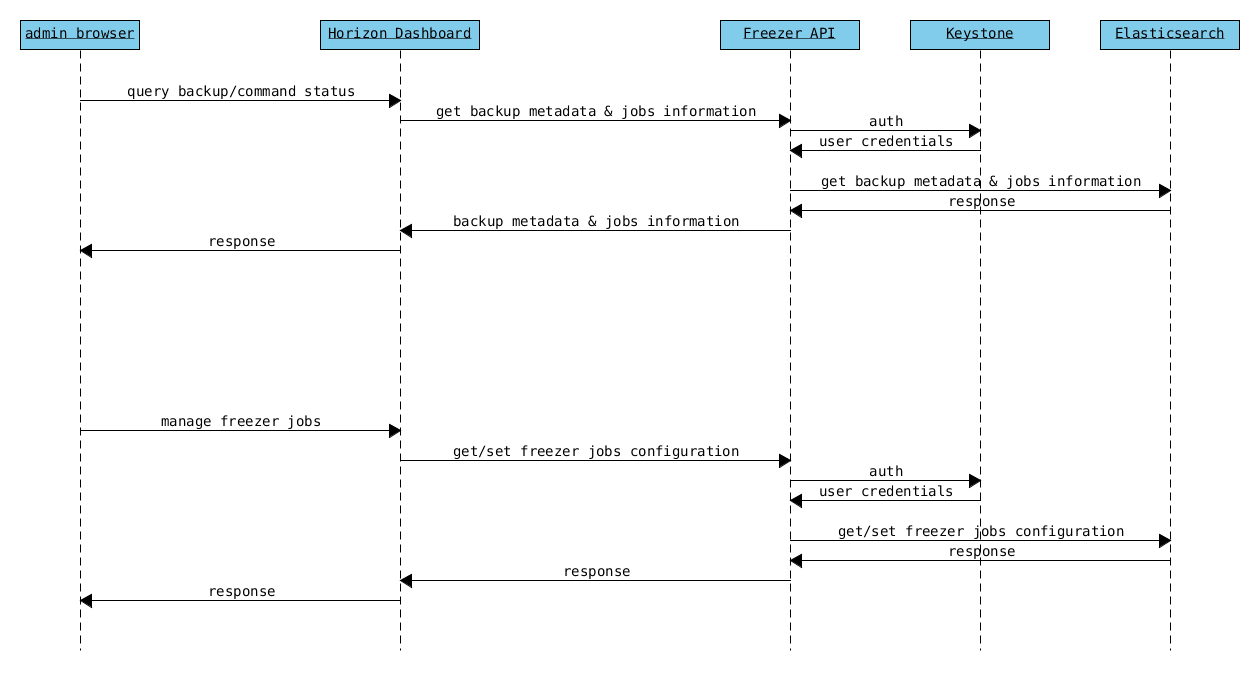
Freezer Dashboard
How to scale
Low resources requirement
Freezer is designed to reduce to the minimum I/O, CPU and Memory Usage. This is achieved by generating a data stream from tar (for archiving) and gzip (for compressing). Freezer segments the stream in a configurable chunk size (with the option --max-seg-size). The default segment size is 64MB, so it can be safely stored in memory, encrypted if the key is provided, and uploaded to Swift as a segment.
Multiple segments are sequentially uploaded using the Swift Manifest. All the segments are uploaded first, and then the Manifest file is uploaded too, so the data segments cannot be accessed directly. This ensures data consistency.
By keeping the segments small, in-memory, I/O usage is reduced. Also as there's no need to store locally the final compressed archive (tar-gziped), no additional or dedicated storage is required for the backup execution. The only additional storage needed is the LVM snapshot size (set by default at 5GB). The lvm snapshot size can be set with the option --lvm-snapsize. It is important to not specify a too small snapshot size, because in case a quantity of data is being written to the source volume and consequently the lvm snapshot is filled up, then the data will be corrupted.
If more memory is available for the backup process, the maximum segment size can be increased. This will speed up the process. Please note that the segments must be smaller then 5GB, since that is the maximum object size in the Swift server.
On the other hand, if a server has small memory availability, the --max-seg-size option can be set to lower values. The unit of this option is in bytes.
How the incremental works
The incremental backups is one of the most crucial features. The following basic logic happens when Freezer executes:
- Freezer starts the execution and checks if the provided backup name for the current node already exists in Swift.
- If the backup exists, then the Manifest file is retrieved. This is important as the Manifest file contains the information of the previous Freezer execution.
Nova and Cinder Backups
If our data is stored on cinder volume or nova instance disk, we can implement file backup using nova snapshots or volume backups.
Nova backups
If you provide nova arguments in the parameters, freezer assumes that all necessary data is located on instance disk and it can be successfully stored using nova snapshot mechanism.
For example if we want to store our MySQL located on instance disk, we will execute the same actions as in the case of lvm or tar snapshots, but we will invoke nova snapshot instead of lvm or tar.
After that we will place the snapshot in a Swift container as a dynamic large object.
container/<instance_id>/<timestamp> <- large object with metadata container_segments/<instance_id>/<timestamp>/segments...
Restore will create a snapshot from stored data and restore an instance from this snapshot. Instance will have different id and old instance should be terminated manually.
Cinder backups
Cinder has its own mechanism for backups, and freezer supports it. But it also allows creating a glance image from volume and uploading to swift.
To use standard cinder backups please provide --cindernative-vol-id argument.
Parallel backup
Parallel backup can be executed only by config file. In config file you should create n additional sections that start with "storage:"
Example [storage:my_storage1], [storage:ssh], [storage:storage3]
Each storage section should have 'container' argument and all parameters related to the storage
Example: ssh-username, ssh-port
For swift storage you should provide additional parameter called 'osrc' Osrc should be a path to file with OpenStack Credentials like:
unset OS_DOMAIN_NAME
export OS_AUTH_URL=http://url:5000/v3
export OS_PROJECT_NAME=project_name
export OS_USERNAME=username
export OS_PASSWORD=secret_password
export OS_PROJECT_DOMAIN_NAME=Default
export OS_USER_DOMAIN_NAME=Default
export OS_IDENTITY_API_VERSION=3
export OS_AUTH_VERSION=3
export OS_CACERT=/etc/ssl/certs/ca-certificates.crt
export OS_ENDPOINT_TYPE=internalURLExample of Config file for two local storages and one swift storage:
[default]
action = backup
mode = fs
path_to_backup = /foo/
backup_name = mytest6
always_level = 2
max_segment_size = 67108864
container = /tmp/backup/
storage = local
[storage:first]
storage=local
container = /tmp/backup1/
[storage:second]
storage=local
container = /tmp/backup2/
[storage:swift]
storage=swift
container = test
osrc = openrc.osrcfreezer-scheduler
The freezer-scheduler is one of the two freezer components which is run on the client nodes; the other one being the freezer-agent. It has a double role: it is used both to start the scheduler process, and as a cli-tool which allows the user to interact with the API.
The freezer-scheduler process can be started/stopped in daemon mode using the usual positional arguments:
freezer-scheduler start|stopIt can be also be started as a foreground process using the
--no-daemon flag:
freezer-scheduler --no-daemon startThis can be useful for testing purposes, when launched in a Docker container, or by a babysitting process such as systemd.
The cli-tool version is used to manage the jobs in the API. A "job" is basically a container; a document which contains one or more "actions".
An action contains the instructions for the freezer-agent. They are the same parameters that would be passed to the agent on the command line. For example: "backup_name", "path_to_backup", "max_level"
To sum it up, a job is a sequence of parameters that the scheduler pulls from the API and passes to a newly spawned freezer-agent process at the right time.
The scheduler understands the "scheduling" part of the job document, which it uses to actually schedule the job, while the rest of the parameters are substantially opaque.
It may also be useful to use the -c parameter to specify
the client-id that the scheduler will use when interacting with the
API.
The purpose of the client-id is to associate a job with the scheduler instance which is supposed to execute that job.
A single OpenStack user could manage different resources on different nodes (and actually may even have different freezer-scheduler instances running on the same node with different local privileges, for example), and the client-id allows him to associate the specific scheduler instance with its specific jobs.
When not provided with a custom client-id, the scheduler falls back to the default which is composed from the tenant-id and the hostname of the machine on which it is running.
The first step to use the scheduler is creating a document with the job:
cat test_job.json
{
"job_actions": [
{
"freezer_action": {
"action": "backup",
"mode": "fs",
"backup_name": "backup1",
"path_to_backup": "/home/me/datadir",
"container": "schedule_backups",
"log_file": "/home/me/.freezer/freezer.log"
},
"max_retries": 3,
"max_retries_interval": 60
}
],
"job_schedule": {
"schedule_interval": "4 hours",
"schedule_start_date": "2015-08-16T17:58:00"
},
"description": "schedule_backups 6"
}Then upload that job into the API:
freezer-scheduler -c node12 job-create --file test_job.jsonThe newly created job can be found with:
freezer-scheduler -c node12 job-list
+----------------------------------+--------------------+-----------+--------+-------+--------+------------+
| job_id | description | # actions | status | event | result | session_id |
+----------------------------------+--------------------+-----------+--------+-------+--------+------------+
| 07999ea33a494ccf84590191d6fe850c | schedule_backups 6 | 1 | | | | |
+----------------------------------+--------------------+-----------+--------+-------+--------+------------+Its content can be read with:
freezer-scheduler -c node12 job-get -j 07999ea33a494ccf84590191d6fe850cThe scheduler can be started on the target node with:
freezer-scheduler -c node12 -i 15 -f ~/job_dir startThe scheduler could have already been started. As soon as the freezer-scheduler contacts the API, it fetches the job and schedules it.
Misc
Dependencies notes
In stable/kilo and stable/liberty the module
pep3143daemon is imported from local path rather than pip.
This generated many issues as the package is not in the
global-requirements.txt of kilo and liberty.
Also pbr in the kilo release does not support env markers which further complicated the installation.
Please check the FAQ too.
Available options:
usage: freezer-agent [-h] [--action ACTION] [--always-level ALWAYS_LEVEL]
[--backup-name BACKUP_NAME]
[--cinder-vol-id CINDER_VOL_ID]
[--cindernative-vol-id CINDERNATIVE_VOL_ID]
[--command COMMAND] [--compression COMPRESSION]
[--config CONFIG] [--config-dir DIR] [--config-file PATH]
[--container CONTAINER] [--debug]
[--dereference-symlink DEREFERENCE_SYMLINK]
[--download-limit DOWNLOAD_LIMIT] [--dry-run]
[--encrypt-pass-file ENCRYPT_PASS_FILE]
[--exclude EXCLUDE] [--hostname HOSTNAME] [--insecure]
[--log-config-append PATH]
[--log-date-format DATE_FORMAT] [--log-dir LOG_DIR]
[--log-file PATH] [--log-format FORMAT]
[--lvm-auto-snap LVM_AUTO_SNAP]
[--lvm-dirmount LVM_DIRMOUNT]
[--lvm-snap-perm LVM_SNAPPERM]
[--lvm-snapname LVM_SNAPNAME]
[--lvm-snapsize LVM_SNAPSIZE] [--lvm-srcvol LVM_SRCVOL]
[--lvm-volgroup LVM_VOLGROUP] [--max-level MAX_LEVEL]
[--max-priority MAX_PRIORITY]
[--max-segment-size MAX_SEGMENT_SIZE]
[--metadata-out METADATA_OUT] [--mode MODE]
[--mysql-conf MYSQL_CONF]
[--no-incremental NO_INCREMENTAL] [--nodebug]
[--nodry-run] [--noinsecure] [--nooverwrite] [--noquiet]
[--nouse-syslog] [--nouse-syslog-rfc-format]
[--nova-inst-id NOVA_INST_ID] [--noverbose]
[--nowatch-log-file]
[--os-identity-api-version OS_IDENTITY_API_VERSION]
[--overwrite] [--path-to-backup PATH_TO_BACKUP]
[--proxy PROXY] [--quiet]
[--remove-from-date REMOVE_FROM_DATE]
[--remove-older-than REMOVE_OLDER_THAN]
[--restart-always-level RESTART_ALWAYS_LEVEL]
[--restore-abs-path RESTORE_ABS_PATH]
[--restore-from-date RESTORE_FROM_DATE]
[--snapshot SNAPSHOT] [--sql-server-conf SQL_SERVER_CONF]
[--ssh-host SSH_HOST] [--ssh-key SSH_KEY]
[--ssh-port SSH_PORT] [--ssh-username SSH_USERNAME]
[--storage STORAGE]
[--syslog-log-facility SYSLOG_LOG_FACILITY]
[--upload-limit UPLOAD_LIMIT] [--use-syslog]
[--use-syslog-rfc-format] [--verbose] [--version]
[--watch-log-file]- optional arguments:
-
-h, --help show this help message and exit --action ACTION Set the action to be taken. backup and restore are self explanatory, info is used to retrieve info from the storage media, exec is used to execute a script, while admin is used to delete old backups and other admin actions. Default backup. --always-level ALWAYS_LEVEL Set backup maximum level used with tar to implement incremental backup. If a level 3 is specified, the backup will be executed from level 0 to level 3 and to that point always a backup level 3 will be executed. It will not restart from level 0. This option has precedence over --max-backup-level. Default False (Disabled) --backup-name BACKUP_NAME, -N BACKUP_NAME The backup name you want to use to identify your backup on Swift --cinder-vol-id CINDER_VOL_ID Id of cinder volume for backup --cindernative-vol-id CINDERNATIVE_VOL_ID Id of cinder volume for native backup --command COMMAND Command executed by exec action --compression COMPRESSION compression algorithm to use. gzip is default algorithm --config CONFIG Config file abs path. Option arguments are provided from config file. When config file is used any option from command line provided take precedence. --config-dir DIR Path to a config directory to pull *.conf files from. This file set is sorted, so as to provide a predictable parse order if individual options are over-ridden. The set is parsed after the file(s) specified via previous --config-file, arguments hence over-ridden options in the directory take precedence. --config-file PATH Path to a config file to use. Multiple config files can be specified, with values in later files taking precedence. Defaults to None. --container CONTAINER, -C CONTAINER The Swift container (or path to local storage) used to upload files to --debug, -d If set to true, the logging level will be set to DEBUG instead of the default INFO level. --dereference-symlink DEREFERENCE_SYMLINK Follow hard and soft links and archive and dump the files they refer to. Default False. --download-limit DOWNLOAD_LIMIT Download bandwidth limit in Bytes per sec. Can be invoked with dimensions (10K, 120M, 10G). --dry-run Do everything except writing or removing objects --encrypt-pass-file ENCRYPT_PASS_FILE Passing a private key to this option, allow you to encrypt the files before to be uploaded in Swift. Default do not encrypt. --exclude EXCLUDE Exclude files,given as a PATTERN.Ex: --exclude '*.log' will exclude any file with name ending with .log. Default no exclude --hostname HOSTNAME, --restore_from_host HOSTNAME Set hostname to execute actions. If you are executing freezer from one host but you want to delete objects belonging to another host then you can set this option that hostname and execute appropriate actions. Default current node hostname. --insecure Allow to access swift servers without checking SSL certs. --log-config-append PATH, --log_config PATH The name of a logging configuration file. This file is appended to any existing logging configuration files. For details about logging configuration files, see the Python logging module documentation. Note that when logging configuration files are used all logging configuration is defined in the configuration file and other logging configuration options are ignored. --log-date-format DATE_FORMAT Defines the format string for %(asctime)s in log records. Default: None . This option is ignored if log_config_append is set. --log-dir LOG_DIR, --logdir LOG_DIR (Optional) The base directory used for relative log_file paths. This option is ignored if log_config_append is set. --log-file PATH, --logfile PATH (Optional) Name of log file to send logging output to. If no default is set, logging will go to stderr as defined by use_stderr. This option is ignored if log_config_append is set. --lvm-dirmount LVM_DIRMOUNT Set the directory you want to mount the lvm snapshot to. If not provided, a unique name will be generated with thebasename /var/lib/freezer --lvm-snap-perm LVM_SNAPPERM Set the lvm snapshot permission to use. If the permission is set to ro The snapshot will be immutable - read only -. If the permission is set to rw it will be mutable --lvm-snapname LVM_SNAPNAME Set the name of the snapshot that will be created. If not provided, a unique name will be generated. --lvm-snapsize LVM_SNAPSIZE Set the lvm snapshot size when creating a new snapshot. Please add G for Gigabytes or M for Megabytes, i.e. 500M or 8G. It is also possible to use percentages as with the -l option of lvm, i.e. 80%FREE Default 1G. --lvm-srcvol LVM_SRCVOL Set the lvm volume you want to take a snaphost from. Default no volume --lvm-volgroup LVM_VOLGROUP Specify the volume group of your logical volume. This is important to mount your snapshot volume. Default not set --max-level MAX_LEVEL Set the backup level used with tar to implement incremental backup. If a level 1 is specified but no level 0 is already available, a level 0 will be done and subsequently backs to level 1. Default 0 (No Incremental) --max-priority MAX_PRIORITY Set the cpu process to the highest priority (i.e. -20 on Linux) and real-time for I/O. The process priority will be set only if nice and ionice are installed Default disabled. Use with caution. --max-segment-size MAX_SEGMENT_SIZE, -M MAX_SEGMENT_SIZE Set the maximum file chunk size in bytes to upload to swift Default 33554432 bytes (32MB) --metadata-out METADATA_OUT Set the filename to which write the metadata regarding the backup metrics. Use '-' to output to standard output. --mode MODE, -m MODE Set the technology to back from. Options are, fs (filesystem),mongo (MongoDB), mysql (MySQL), sqlserver (SQL Server) Default set to fs --mysql-conf MYSQL_CONF Set the MySQL configuration file where freezer retrieve important information as db_name, user, password, host, port. Following is an example of config file: # backup_mysql_confhost = <db-host>user = <mysqluser>password = <mysqlpass>port = <db-port> --no-incremental NO_INCREMENTAL Disable incremental feature. By default freezer build the meta data even for level 0 backup. By setting this option incremental meta data is not created at all. Default disabled --nodebug The inverse of --debug --nodry-run The inverse of --dry-run --noinsecure The inverse of --insecure --nooverwrite The inverse of --overwrite --noquiet The inverse of --quiet --nouse-syslog The inverse of --use-syslog --nouse-syslog-rfc-format The inverse of --use-syslog-rfc-format --nova-inst-id NOVA_INST_ID Id of nova instance for backup --noverbose The inverse of --verbose --nowatch-log-file The inverse of --watch-log-file --os-identity-api-version OS_IDENTITY_API_VERSION, --os_auth_ver OS_IDENTITY_API_VERSION OpenStack identity api version, can be 1, 2, 2.0 or 3 --overwrite With overwrite removes files from restore path before restore. --path-to-backup PATH_TO_BACKUP, -F PATH_TO_BACKUP The file or directory you want to back up to Swift --proxy PROXY Enforce proxy that alters system HTTP_PROXY and HTTPS_PROXY, use '' to eliminate all system proxies --quiet, -q Suppress error messages --remove-from-date REMOVE_FROM_DATE Checks the specified container and removes objects older than the provided datetime in the form 'YYYY-MM- DDThh:mm:ss' i.e. '1974-03-25T23:23:23'. Make sure the 'T' is between date and time --remove-older-than REMOVE_OLDER_THAN, -R REMOVE_OLDER_THAN Checks in the specified container for object older than the specified days. If i.e. 30 is specified, it will remove the remote object older than 30 days. Default False (Disabled) --restart-always-level RESTART_ALWAYS_LEVEL Restart the backup from level 0 after n days. Valid only if --always-level option if set. If --always- level is used together with --remove-older-than, there might be the chance where the initial level 0 will be removed. Default False (Disabled) --restore-abs-path RESTORE_ABS_PATH Set the absolute path where you want your data restored. Default False. --restore-from-date RESTORE_FROM_DATE Set the date of the backup from which you want to restore.This will select the most recent backup previous to the specified date (included). Example: if the last backup was created at '2016-03-22T14:29:01' and restore-from-date is set to '2016-03-22T14:29:01', the backup will be restored successfully. The same for any date after that, even if the provided date is in the future. However if restore-from-date is set to '2016-03-22T14:29:00' or before, that backup will not be found. Please provide datetime in format 'YYYY-MM- DDThh:mm:ss' i.e. '1979-10-03T23:23:23'. Make sure the 'T' is between date and time Default None. --snapshot SNAPSHOT, -s SNAPSHOT Create a snapshot of the fs containing the resource to backup. When used, the lvm parameters will be guessed and/or the default values will be used, on windows it will invoke vssadmin --sql-server-conf SQL_SERVER_CONF Set the SQL Server configuration file where freezer retrieve the sql server instance. Following is an example of config file: instance = <db-instance> --ssh-host SSH_HOST Remote host for ssh storage only --ssh-key SSH_KEY Path to ssh-key for ssh storage only --ssh-port SSH_PORT Remote port for ssh storage only (default 22) --endpoint Endpoint of S3 compatible storage --access-key Access key for S3 compatible storage --secret-key Secret key for S3 compatible storage --ssh-username SSH_USERNAME Remote username for ssh storage only --storage STORAGE Storage for backups. Can be Swift, Local, SSH and S3 compatible now. Swift is default storage now. Local stores backups on the same defined path and swift, s3 will store files in container. --syslog-log-facility SYSLOG_LOG_FACILITY Syslog facility to receive log lines. This option is ignored if log_config_append is set. --upload-limit UPLOAD_LIMIT Upload bandwidth limit in Bytes per sec. Can be invoked with dimensions (10K, 120M, 10G). --use-syslog Use syslog for logging. Existing syslog format is DEPRECATED and will be changed later to honor RFC5424. This option is ignored if log_config_append is set. --use-syslog-rfc-format Enables or disables syslog rfc5424 format for logging. If enabled, prefixes the MSG part of the syslog message with APP-NAME (RFC5424). This option is ignored if log_config_append is set. --verbose, -v If set to false, the logging level will be set to WARNING instead of the default INFO level. --version show program's version number and exit --watch-log-file Uses logging handler designed to watch file system. When log file is moved or removed this handler will open a new log file with specified path instantaneously. It makes sense only if log_file option is specified and Linux platform is used. This option is ignored if log_config_append is set.
Scheduler Options
To get an updated sample of freezer-scheduler configuration you the following command:
oslo-config-generator --config-file config-generator/scheduler.confyou will find the update sample file in etc/scheduler.conf.sample
Agent Options
To list options available in freezer-agent use the following command:
oslo-config-generator --namespace freezer --namespace oslo.logthis will print all options to the screen you direct the output to a file if you want:
oslo-config-generator --namespace freezer --namespace oslo.log --output-file etc/agent.conf.sampleBandwidth limitation (Trickle)
Trickle for bandwidth limiting (How it works ):
We have 3 cases to handle:
- User used
--upload-limitor--download-limitfrom the CLI - User used configuration files to execute an action
- A combination of both of these options.
User used --upload-limit or -download-limit from the CLI
We need to remove these limits from the cli arguments and then run trickle using subprocess
EX:
# freezer-agent --action backup -F /etc/ -C freezer --upload-limit = 1kthis will be translated to:
# trickle -u 1024 -d -1 freezer-agent --action backup -F /etc/ -C freezerUser used config files to execute an action
We need to create a new config file without the limits So we will get the all the arguments provided and remove limits then run trickle using subprocess
EX: We have a config file contains:
[default]
action = backup
storage = ssh
ssh_host = 127.0.0.1
ssh_username = saad
ssh_key = /home/saad/.ssh/saad
container = /home/saad/backups_freezers
backup_name = freezer_jobs
path_to_backup = /etc
upload_limit=2k
download_limit=1kand we are going to execute this job as follow:
freezer-agent --config /home/user/job1.inithis will be translated to:
trickle -u 2048 -d 1024 freezer-agent --config /tmp/freezer_job_x21aj29The new config file has the following arguments:
[default]
action = backup
storage = ssh
ssh_host = 127.0.0.1
ssh_username = saad
ssh_key = /home/saad/.ssh/saad
container = /home/saad/backups_freezers
backup_name = freezer_jobs
path_to_backup = /etcHybrid approach using config file and CLI options
We will use a mix of both procedures:
- remove limits (cli or config )
- reproduce the same command again with trickle
EX:
$ freezer-agent --config /home/user/job2.ini --upload-limit 1kThe Freezer logo is released under the licence Attribution 3.0 Unported (CC BY3.0).