fixing the double-quote chars in the RST source to be regular double-quotes Change-Id: Iaeb652d63d093091af9f321e421fd082948c5614
51 KiB
Artifact Repository
https://blueprints.launchpad.net/glance/+spec/artifact-repository
Extend Glance's functionality to store not only the VM images but any other artifacts, i.e binary objects accompanied with composite metadata.
Glance should become a catalog of such artifacts, providing capabilities to store, search and retrieve their artifacts, their metadata and associated binary objects.
Problem description
Various OpenStack services often need to catalog different objects they use to operate. Such objects may contain various data as well as metadata needed for identification and description.
Images used by Nova to run the VMs are just the best known examples of such objects. Other examples include Heat templates, Solum Plan Files, Mistral Workbooks, Murano Application Packages etc.
- "To catalog" means to have the following functionality:
-
- To store the object reliably
- To guarantee its immutabity once it is stored
- To provide search capabilities to find the objects in catalog
- To return the detailed info about the requested object
- To allow fetching the object for usage by a Service
- To control the access to the object: enforce usage and modification policies, publication scenarios etc
- To manage the object lifecyle
Obviously, this set of functionality is common for different kinds of objects, and is usually unrelated to the primary mission of respective projects using these objects. That is why it is suggested to have a dedicated service which will provide the catalog functionality for other OpenStack services. As Glance already serves as a catalog of Images for Nova, it is suggested to extend its mission so it may serve as a catalog for other services as well.
The objects stored in the catalog are called Artifacts, and the catalog itself – Artifact Repository.
Proposed change
It is proposed to add Artifact Repository functionality to Glance, i.e. create a set of APIs, data models and services which will allow to store artifacts of different types in Glance.
It is required to introduce the following concepts and behaviors:
Artifact
Artifact is a block of binary data stored with a description – metadata.
All artifacts should have the following properties:
- Artifacts shall be consumable by OpenStack services. Like Nova uses Images to run the VMs, so will other existing or upcoming OpenStack services use different kinds of Artifacts. Ability to be consumed by the services is important: data chunks which are not consumable by other services (e.g. user data) are NOT artifacts. If one is looking to store such unrelated data then Swift (or any other generic object storage) should be a proper choice.
- Artifacts description (metadata) should have a well-defined, discoverable structure. Artifacts’ metadata should contain only the fixed set of fields. Different types of artifacts may have different sets of allowed fields, but attaching unexpected values should be prohibited.
- Artifacts are immutable. I.e. once the artifact is made available, there should be no way to change its binary content and at least some meaningful parts of its metadata. So once the consumer has discovered an artifact, its content is guaranteed to remain the same during the whole life of the object, and no other object may get the same ID. The artifact may be deleted, but any modifications introduced will result in creating a new object with a new ID.
Note: To properly handle modification scenarios it is advised not to delete the existing artifact, but to create the new version of it. See the "Artifact Versions" section below
Artifact types
Type of the Artifact defines its purpose and contents. It is defined by the OpenStack service which is supposed to use the artifact, however the mapping between an Artifact type and a Service is not one-to-one: a single service may utilise a number of different artifact types, and in some cases the same types of artifact may be consumed by different services.
Examples of Artifact types include Images (consumed by Nova), Templates (consumed by Heat and other services working on top of the Heat, such as Solum or Murano), Solum plan files (consumed by Solum), Application Packages (consumed by Murano Application Catalog) etc. The type of artifact defines the structure of both its binary data and metadata. Some of the repository operations may also be defined per artifact type and may have different behaviour for different types.
The new types of artifacts may be added. This will be implemented using a plugin system. Each plugin defines one or more of the artifact types and completely describes their data structure, metadata-scheme and actions.
Artifact types supported by the particular Glance repository, as well as the structure and available actions of a particular type should be discoverable via a set of special API calls.
Artifact plugin
A plugin is a python module which defines one or more Artifact Types, with their custom metadata fields, BLOB kinds, custom validation logic etc (see respective sections below).
Glance uses stevedore library to discover the artifact types defined in the plugins. Each endpoint defined in the plugin identifies the Artifact Type being exported. The name of the each endpoint should be equal to the name of the artifact type. All the endpoints should belong to glance.artifacts.types namespace.
Each Artifact Type has a version assigned to it. From code point of view each version of the same Artifact Type is a different python class with different value of version-identifying attribute. A single plugin may contain definitions of several versions of the same Artifact Type. Also, different versions of the same Artifact Type may be defined in different plugins: it is up to the plugin developers to decide which composition suits their needs better.
If the plugin contains a single version of some artifact type then the corresponding endpoint should export the class definition of this particular type with type name matching the endpoint name.
If the plugin contains multiple versions of the artifact type then the corresponding endpoint should export a list of class definitions, and each of these classes should have distinct type version values and identical type name, all equal to the name of endpoint.
A given version of specific artifact type may be defined only in a single plugin, i.e. if there may be no second plugin defining the same artifact type with the same version.
At startup Glance will inspect all the enabled plugins and ensure that no artifact-type conflict occurs. If several active plugins define the same artifact type and version, the critical exception occures and artifact's server does not start. It is up to the operator to resolve the conflict and uninstall the unnecessary plugin(s).
To enable a plugin the cloud operator has to install the python module into the python environment of the node which runs Glance and make appropriate changes into the configuration files.
Only the types from explicitly enabled plugins are available for usage.
Metadata Structure
The metadata describing the artifacts has to have a predefined and discoverable structure. Some of the metadata fields are common for all the types of Artifacts, while the others are defined for particular types only.
Some of the fields are immutable: i.e. their value can be changed only while the artifact is being interactively created (see below) and is fixed since the moment once the artifact is published in the repository. Other fields may be modified at any time. Also there are system fields which cannot be modified at any time - their value is set automatically by the repository.
| Name | Access | Required | Data type | Description |
|---|---|---|---|---|
| ID | System | N/A | UUID String | Identifies the artifact in the repository. Is assigned automatically once the artifact's draft is registered. Is not supposed to be explicitly set by the user, however administrators may override this value if needed. |
| Type | Immutable | Yes | Alphanumeric string, valid artifact type name | Identifies the type of artifact, and so its data and metadata structure should be one of the types supported by the repository (handled by the active plugins) |
TypeVersion |
System |
N/A |
String following SemVer notation |
A system field defining the version of artifact type, i.e. the version of the plugin which contains the artifact type definition. The value is set automatically when the artifact record is created. In future, this may be used to do automatic or manual migrations of artifacts data and metadata. |
| Name | Immutable | Yes | Alphanumeric string, 255 characters max | Defines the name of the artifact. In the future certain uniquiness of (name, version) will be guaranteed, so that it will be capable of identifying the artifact within a catalog. |
| Version | Immutable | Yes | String following the SemVer notation | Defines the version of the artifact. See "Artifact versioning" section below for the details. |
| Description | Mutable | No | String | Arbitrary text describing the artifact, 255 characters max |
| Tags | Mutable | No | Set of alphanumeric strings, each 255 characters max | A set of arbitrary string labels associated with the artifact for search and filter capabilities |
| Visibility | Mutable | Yes | Enum, any of PRIVATE, PUBLIC | A field indicating if the artifact is accessible for all the tenants in the cloud (PUBLIC), or for its owner only (PRIVATE). |
| State | System | N/A | Enum, any of: CREATING, ACTIVE, DEACTIVATED, DELETED | A system field set by the repository, indicating the current phase of the artifact's lifecycle. See "Artifact Lifecyle" below for details |
| Owner | System | N/A | String, OpenStack tenant (project) identifier | An identifier of the tenant (project) to which the artifact has been uploaded |
| CreatedAt | System | N/A | Timestamp | Time when the artifact record was created in the repository. Never changes once set |
| UpdatedAt | System | N/A | Timestamp | Time when the artifact was last modified. Is updated automatically by repository on every operation which updates the artifact record or its relatives. |
| PublishedAt | System | N/A | Timestamp | Time when the artifact was published, i.e. moved from CREATING to ACTIVE state. Empty for artifacts in CREATING state |
| DeletedAt | System | N/A | Timestamp | Time when the artifact was deleted, i.e. moved from CREATING, ACTIVE or DEACTIVATED state to DELETED. Is empty for artifacts not in DELETED state |
Type-specific metadata fields
For each type of artifact, additional metadata fields may be defined. This set of fields and their properties are specified by the artifact types. The plugin which defines the artifact defines all its type-specific fields. Each type-specific metadata field is represented by a data structure having the following properties:
Field name - alphanumeric value identifying the field. Should be unique per artifact type
Field type - a type of the data stored in the field. Identifies the types of queries which may be made to search and filter the artifacts in catalog. The following types are supported:
- String - simple string value (255 characters max). In listing queries may use this field to filter artifacts by value equality (e.g. "filter all the artifacts of type ‘Image’ having the field ‘OS_TYPE’ equal to ‘Linux’")
- Integer. - integer field. In listing queries may use this field to filter artifacts by both value equality and value range (e.g. "filter all the artifacts of type ‘Image’ having the field ‘REQUIRED_RAM’ less or equal to 16")
- Numeric - same as Integer, but stored as Numeric
- Boolean* - boolean values, having either 'True' or 'False' as the value. In listing queries may use this field to filter artifacts by value equality.
- Text - Long text field. May not be used for filtering, just stores arbitrary large text descriptions, JSONs etc. The loading of these fields from the Database should be deferred when the artifacts are listed, taken for modification etc - they should be loaded only when the client request the contents of the artifact. This reduces the load on Database. Additionally the plugin developers may put custom constraints to limit the length of the text.
- Array - a list of values of some specific type (String, Text, Integer, Numeric, Boolean) or their combination. Such field may be used for tag-like filtering semantics (i.e. the artifacts of some type may have a set field called ‘Category’, each such artifact may have a number of categories assigned, and the filtering query may be made to list only the artifacts having the specific category)
- Dict - a set of key-value pairs, where key are string values (255 chars max) while values may be any of String, Text, Integer, Numeric or Boolean. May be used for filtering the artifacts by having specific value of some key or by just having some specific key with any value.
Required - boolean value indicating if the field value should be specified for the artifact to be valid.
Mutable - boolean value indicating if the field value may be changed after the artifact is published.
Internal - a boolean value indicating that the value of this field is not shown to the end-user (cannot be fetched using API or used in queries), but may be accessed internally by the plugin logic.
Default - a default value for the field may be specified by the Artifact Type.
Allowed values - a list of possible values for the field to store
Constraints - a number of constraints may be defined for each metadata field. Available constraints depend on the field type:
- String - minLength, maxLength, pattern
- Integer and Numeric - minimum, maximum values
- Array - types of the elements (either a single type for all the elements or specific type for each element), minimum and maximum numbers of elements in the array, type-specific constrains for elements.
- Dict - types of the values (either a single type for all the values of specific type for each value), minimum and maximum numbers of values in the dict, type-specific constrains for values.
Also, custom, code-driven constrains may be defined for each field by the plugin developer.
Artifact Versions
The Artifact repository is able to store different versions of the same artifact. From repository's point of view these are different objects (having different IDs, stored independently and having independent lifecycle), but having the same type and name, but different version fields.
The version field is one of common immutable metadata fields (see above). It follows the SemVer notation, i.e. its value is composed out of 3 numeric parts (major version, minor version and patch, with optional alphanumeric prerelease suffix), e.g. 5.1.3 or 1.1.4-alpha. An order is defined between version values according to the SemVer spec, e.g. 1.2.3 > 1.2.2, 1.0.1 < 1.1.0, 1.0.0 > 1.0.0-some-suffix etc, according to spec. When the version is specified, some of its parts may be omitted: e.g. 10 will stand for 10.0.0, 5.1 will stand for 5.1.0. The repository will accept such an input and will convert it to the fill semver notation. The major version part is mandatory. Either major or minor parts should be non-zero: e.g. 0.1 is possible while 0.0 is not.
Binary Data
The data is the heart and soul of artifacts and the primary reason of their existence. Sometimes it is just a simple text (or XML, YAML or JSON object represented as text) which may be stored in the artifact's additional metadata fields, however in many cases it is a large binary object, such as VM image or other large block of bytes. And even textual data is often completely unrelated to artifact's metadata - and thus has to be treated separately.
Be the data really binary or textual it should be stored independently from the artifact record in some dedicated storage system - in a same manner as VM images are stored independently from their definitions in the current version of Glance.
When the artifact is initially created in the repository (the record is inserted into the database), it is in the CREATING state (see the "Artifact Lifecycle" section below) and has no binary data associated. Then - before publishing the artifact - its owner may upload the data by using the appropriate API calls or specify the location/uri of the existing binary blob pre-uploaded to some back-end storage. If the new blobs are uploaded, they will be placed into the storage system (the one which is being used for the particular instance of Glance) and associated with the artifact record by using its id. If the existing location/uri is passed, only the association will be made.
When the artifact repository is browsed, only the artifact metadata is returned: the data objects for each specific artifact have to be downloaded separately, by sending an appropriate API calls either to Glance or directly to the appropriate underlying storage system.
Unlike the current Glance Images, a single artifact may have more than one binary object associated.
For example, a Heat template, being stored as an artifact, may require a Heat template itself, a number of provider templates, plus, probably, an Icon to be displayed in the catalog UI. All of these are considered to be "artifact's data" (although the templates are not actually binary), and there is no sense in merging them into a single block of data: different templates may be required at different moments of time, while the icon is needed in UI only - so they are stored as different "binary objects" and are retrieved one-by-one when really needed
This means that each artifact may have a number of different BLOBs associated.
The amount of blobs and their types ("Heat template", "Provider Templates" and "Icon" in the example above) are defined per each artifact type. When the artifact is in CREATING state its owner will have to upload all the required parts one-by-one, specifying their types every time. If some required blob is not uploaded, the "publishing check" will not pass and the artifact will not be accepted into the repository. So, in general, this is similar to specifying the values of additional type-specific metadata fields.
For each artifact type its plugin can define several BLOB properties that correspond to the BLOBs supported by this particular type. BLOB properties can be defined in 2 forms - either as a single BinaryObject, or as BinaryObjectList. The latter can be constrained with maximum and minimum length. Each BLOB property is represented by a data structure having the following properties:
Name (alphanumeric string) - name of the blob property. Should be unique per artifact type.
Required (boolean) - a flag indicating if the blob(s) of this property is required for the artifact to be valid.
Minimum Length (for BinaryObjectList only) (a positive integer value or None) - specifies the minimal required amount of blobs per artifact. If set to None, then the number of blobs in BLOBs list per artifact has no lower bound.
Maximum Length (for BinaryObjectList only) (a positive integer value or None) - specifies the maximum amount of blobs per artifact. If set to None, then the number of blobs in BLOBs list per artifact has no upper bound.
For example, the above-mentioned artifact type "Heat template" may define an optional BinaryObjectList property with the Name set to "ProviderTemplate", and a required BinaryObjectList property with the name "Icon" and minimum and maximum length constraints equal to 1. This means that the artifacts of this type have to contain exactly one icon blob and zero or more provider template blobs.
The repository provides an API call to inspect the blob contents of each artifact.
In the example above the API returns a dictionary containing two keys: "ProviderTemplates" and "Icon". The first key defined a list of records, each one corresponding to a different blob with a provider template, the second one defines a single record corresponding to the blob with the icon. Each of the blob records contains an id of the particular blob, which may be used to download the blob.
Binary data is immutable, and no new blobs may be added as well as no existing blobs may be deleted once the artifact is moved to the ACTIVE state. When the artifact is deleted, all its blobs are deleted as well. The blob data is accessible to a user only if they have permission to access the artifact containing that blob.
Artifact Dependency Relations
In OpenStack ecosystems the entities rarely go alone: usually they interact with each other. Artifacts aren't different: quite often an artifact may need to work with other artifacts in one way or another. In this case it may be reasonable to introduce a concept of Artifact Dependency: an artifact may depend on any number of other artifacts of any type.
For example there may be an artifact containing a reusable pack of Puppet manifests which configure some common software components on the VMs (artifact A). Another artifact containing some Heat Software Config template (artifact B) may utilise the puppet manifests from the artifact A for some post-deploy configuration actions on the VMs created by the template. In this case artifact B may specify artifact A as its dependency, so the service which is going to use B may detect, that it may need A as well and download it in advance.
This eventually creates chains of transitively-dependent artifacts. An API method provided by Artifact Repository should allow to retrieve all the dependencies of a given artifact. Subsequent calls to the same API will allow to retrieve all the transitive dependencies.
These dependency relations are actually a special kind of artifact metadata: they are stored in repository database together with artifact records. They are immutable, i.e. can be defined only while the artifact is in the CREATING state and cannot be modified after it is published.
The operations to create, view or modify a dependency for a particular artifact should be implemented as a set of APIs similar to other metadata editing.
The dependencies cannot be circular (e.g if A depends on B, B depends on C and C depends on D, then D cannot depend on A), and the published artifact may not depend on an artifact being in a "CREATING" state. For example, if A depends on B and both are in "CREATING" state, then B should be published before A, otherwise the publishing check of A will fail.
The dependencies may be created only on the artifacts which belong to the same tenant as the dependent artifact. Once the dependency is established, a target artifact cannot be deleted before its dependent artifact is deleted. If both are deleted and should be restored, they restoreation should happen in the same order as creation: the target artifact first, the dependent - second.
Artifacts Lifecycle
An Artifact may be in one of the three states, indicating different phases of its lifecycle:
CREATING state indicates that the artifact record has been created in repository (ID was assigned), but the artifact is still being constructed (some fields have to be set, the data uploaded etc). Mutable metadata fields may be modified while the artifact is in this state. The binary data may be uploaded or location uri for pre-uploaded blobs may be specified, the dependencies may be set or modified.
Artifacts in the CREATING state are not visible to tenants other than the owner's even if the 'Visibility' field is set to 'PUBLIC'. When artifact is in the CREATING state its owner may call a 'Publish' API method to publish the artifact. This will validate the artifact and change its state to ACTIVE. When the artifact is in CREATING state its owner may initiate its deletion. This will change the state of the artifact to ‘DELETED’.
ACTIVE state indicates that the artifact is available for use. When the artifact is in this state the immutable metadata fields may not be updated, no new binary data may be uploaded, existing data may not be deleted.
Artifacts in ACTIVE state are visible to other tenants if the 'Visibility' field is set to PUBLIC. When the artifact is in this state it is assumed that it may be used by the third-party services. When the artifact is in ACTIVE state its owner may initiate its deletion. This will change the state of the artifact to ‘DELETED’.
DEACTIVATED state indicates that the artifact which had been previously published has been temporary deactivated (i.e. prevented from being used) by the cloud administrator. Artifact is visible to all the users which may access it regularly (i.e. to its owner and to other tenants if it is made public) and its metadata can be fetched as well, but the binary data is not accessible and the artifact should not be used by third-party services until the deactivation is removed. Usually this is used for investigations of reported problems with artifacts. When the investigation is completed the artifact may be reactivated again (by changing the state back to ACTIVE) or deleted.
DELETED state indicates that the artifact has been deleted and its data and metadata objects are not accessible anymore.
This state is available only if a "delayed_delete" option is enabled in the configuration file, which makes the deletion to be non-immediate: the artifacts are just marked as deleted, however the actual deletion is delayed for the configurable amount of time.
If delayed_delete is disabled, then artifacts do not enter the DELETED state, their records are permanently removed from the repository when the deletion operation is executed.
A state transition diagram can be found here.
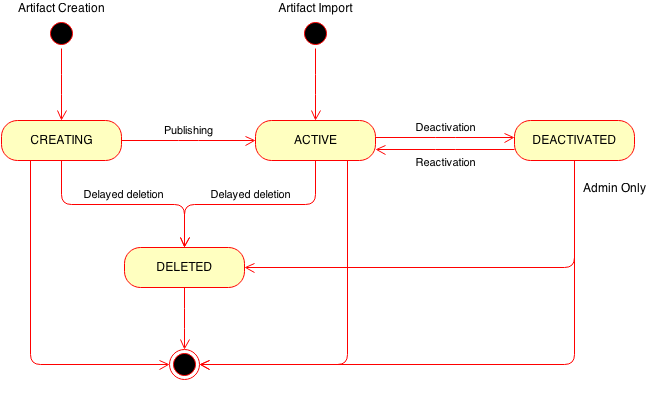{kind=link}
Composing an Artifact
Artifacts may be created using an iterative process, which starts with creating an artifact record in the database. Then a number of APIs may be called to set the values of various metadata properties, upload the binary data, specify the dependency links etc.
While the aftifact is being composed it remains in CREATING state.
Publishing an Artifact
Publishing is an operation which makes an artifact available for usage: when all the metadata fields are set and the binary data parts are uploaded (which may be a lengthly multi-step process), it may be made available by calling a special API method to change its state to ACTIVE.
During the execution of this call Glance will verify that all the dependency relations are set to the existing and already published artifacts. If at least one of the dependencies either does not exist (i.e. the artifact has been deleted after the dependency was created) or is not in the ACTIVE state, then the publishing action will fail.
Deleting an Artifact
An artifact may be deleted only by its owner or a cloud administrator. When the delete action is called, the following actions are executed:
- All the artifacts of the current tenant are inspected. If any of them have a Dependency Relation to the artifact being deleted, the deletion operation is aborted
- If the delayed delete is enabled, artifact's state is set to DELETED and the deletion operation is scheduled to in the configurable time interval
- If the soft delete is not enabled, then a background deletion operation is scheduled to run immediately
The deletion operation (be it delayed or immediate) does the following:
- Delete all the binary data objects of the artifact from the underlying storage system.
- Delete the artifact's record from the database, including all the custom metadata property values, associated tags and outgoing dependency relations
Alternatives
The need of a catalog service seems obvious, however sometimes questions are asked if Glance is appropriate project for this. Some people were suggesting to use a completely separate service for this, some suggested to use Swift instead of Glance.
Why not a separate service?
Because Glance's Images are perfect examples of Artifacts: they are binary objects stored with arbitrary metadata describing them. Glance already provides search and filter capabilities, they just have to be extended to support artifact types other then images.
Why not to use Swift?
For a number of reasons.
First, Swift is not a catalog, it is just an object storeage. There are no search or filter capabilities, object immutability is not guranteed.
Then, Swift has a different level of abstraction: it does not care about the data which is being stored within it, while Glance should be aware of the artifact types specifics.
Last but not least, many production-grade OpenStack deployments do not have Swift deployed, as they do not need it. Meanwhile, Glance is present on each and every OpenStack cloud.
Meanwhile, Swift still may be used as an underlying storage for artifacts - in the same way as Glance uses it to store Images.
Data model impact
This will use a relational database and exist in the same database as the existing Glance relational data, but there is not anticipated impact to existing Glance data models. This is all new functionality.
Support will be added to: * glance/db/sqlalchemy/api.py * registry/api.py * simple/api.py
A new script glance/db/sqlalchemy/artifacts.py will be added
The table classes will be in glance/db/sqlalchemy/models_artifacts.py
The following DB schema is the initial suggested schema. Constraints are not shown for readability.
| Field | Type | Null | Key |
|---|---|---|---|
| id | varchar(36) | NO | PRI |
| name | varchar(255) | NO | MUL |
| type_name | varchar(255) | NO | MUL |
| type_version_prefix | bigint(20) | NO | |
| type_version_suffix | varchar(255) | YES | |
| type_version_meta | varchar(255) | YES | |
| version_prefix | bigint(20) | NO | |
| version_suffix | varchar(255) | YES | |
| version_meta | varchar(255) | YES | |
| description | text | YES | |
| visibility | varchar(32) | NO | MUL |
| state | varchar(32) | NO | MUL |
| owner | varchar(255) | NO | MUL |
| created_at | datetime | NO | |
| updated_at | datetime | NO | |
| published_at | datetime | YES | |
| deleted_at | datetime | YES |
| Field | Type | Null | Key |
|---|---|---|---|
| id | varchar(36) | NO | PRI |
| name | varchar(36) | NO | MUL |
| artifact_id | varchar(36) | NO | MUL |
| size | bigint(20) | NO | |
| position | int(11) | YES | |
| item_key | varchar(329) | YES | MUL |
| checksum | varchar(329) | YES | MUL |
| created_at | datetime | NO | |
| updated_at | datetime | NO |
| Field | Type | Null | Key |
|---|---|---|---|
| id | varchar(36) | NO | PRI |
| value | text | NO | |
| blob_id | varchar(36) | NO | MUL |
| status | varchar(36) | YES | |
| position | int(11) | YES | |
| created_at | datetime | NO | |
| updated_at | datetime | NO |
| Field | Type | Null | Key |
|---|---|---|---|
| id | varchar(36) | NO | PRI |
| artifact_source | varchar(36) | NO | MUL |
| artifact_dest | varchar(36) | NO | MUL |
| artifact_origin | varchar(36) | NO | MUL |
| is_direct | tinyint(1) | NO | |
| position | int(11) | YES | |
| name | varchar(36) | YES | |
| created_at | datetime | NO | |
| updated_at | datetime | NO |
| Field | Type | Null | Key |
|---|---|---|---|
| id | varchar(36) | NO | PRI |
| artifact_id | varchar(36) | NO | MUL |
| string_value | varchar(255) | YES | |
| int_value | int(11) | YES | |
| numeric_value | decimal(10,0) | YES | |
| bool_value | tinyint(1) | YES | |
| text_value | text | YES | |
| position | int(11) | YES | |
| name | varchar(36) | NO | MUL |
| created_at | datetime | NO | |
| updated_at | datetime | NO |
| Field | Type | Null | Key |
|---|---|---|---|
| id | varchar(36) | NO | PRI |
| artifact_id | varchar(36) | NO | MUL |
| value | varchar(255) | YES | |
| created_at | datetime | NO | |
| updated_at | datetime | NO |
REST API impact
All the new APIs to be placed under the /v2/artifacts API branch
All the APIs which are specific to the particular artifact type should be placed to /v2/artifacts/{artifact_type}, where artifact_type is a constant defined by the artifact type definition (i.e. by the plugin), which usually should be plural of the artifact type name. For example, for artifacts of type "template" this constant may be called 'templates', so the API endpoints will start with /v2/artifacts/templates.
The artifact_type constant should unambiguously identify the artifact type, so the values of this constants should be unique among all the artifact types defined by the active plugins.
The artifact_type constant should be followed by type_version identifier containing a SemVer-compliant string prefixed with v, e.g. v1.1.5. This will identify the particular version of the artifact type if there are many of them available. In the "List Artifacts" and "Get an Artifact" API calls the type_version is optional and may be omitted.
- List artifacts
-
- GET /v2/artifacts/{artifact_type}/[{type_version}/]creating - list
-
artifact drafts
Returns the list of artifacts in CREATING state having the specified type and owned by the current tenant. If the user is administrator returns the artifacts in CREATING state owned by all the tenants.
- GET /v2/artifacts/{artifact_type}/[{type_version}/] - list artifacts
-
which are ready for usage
Returns the list of artifacts in ACTIVE state, which are either owned by the current tenant or are made available to everyone with setting Visibility metadata field to PUBLIC.
- GET /v2/artifacts/{artifact_type}/[{type_version}/]deactivated - list
-
artifacts in DEACTIVATED state.
Returns the list of artifacts in DEACTIVATE state which are temporary suspended from usage.
- URL parameters:
-
- artifact_type identifier of the artifact type, should be equal to a
-
valid constant defined in one of the active artifact plugins.
- type_version optional identifier defining the version of artifact type. If omitted all versions of an artifact type are assumed, but sorting and filtering capabilities are limited to generic properties only.
- Query parameters:
-
Query may contain parameters intended for filtering and soring by most of common and type-specific metadata fields. Type-specific fields may be used only if type_version parameter is set to specific version of the artifact type. The set of parameters and their values should be compliant to the schema defined by the artifact type and its version.
Filtering:
Filter keys may be any generic and type-specific metadata fields of primitive type, like 'string', 'numeric', 'int' and 'bool'. But filtering by type-specific properties is allowed only when artifact version is provided.
Direct comparison requires a property name to be specified as query parameter and the filtering value as its value, e.g. ?name=some_name
Parameter names and values are case sensitive.
Artifact API supports filtering operations in format ?name=<op>:some_name, where op is one of the following:
- eq: equal;
- ne: not equal;
- gt: greater than;
- ge: greater or equal than;
- lt: lesser than;
- le: lesser or equal than.
Set comparison filtering is available for all the set-valued type-specific metadata fields as well as common field "tags".
Set comparison requires a property name to be specified as query parameter. The property may be repeated several times, e.g. the query ?tags=abc&tags=cde&tags=qwerty will filter artifacts having either 'abc, 'cde' or 'qwerty' tags associated.
Checking for entry into the array property is performed by in operation. It's done the same way as other filters, e.g. ?items_array=in:array_element.
Sorting
In order to retrieve data in any sort order and direction, artifacts REST API accepts multiple sort keys and directions.
Artifacts API will align with the API Working group sorting guidelines <https://github.com/openstack/api-wg/blob/master/guidelines/ pagination_filter_sort.rst> and support the following parameter on the request:
- sort: Comma-separated list of sort keys, each key is optionally appended with <:dir>, where 'dir' is the direction for the corresponding sort key (supported values are 'asc' for ascending and 'desc' for descending)
Sort keys may be any generic and type-specific metadata fields of primitive type, like 'string', 'numeric', 'int' and 'bool'. But sorting by type-specific properties is allowed only when artifact version is provided.
Default value for sort direction is 'desc', default value for sort key is 'created_at'.
Pagination
limit and marker query parameters may be used to paginate through the artifacts collection in the same way as it is done in the current version of Glance "List Images" API.
Maximum limit number is 1000. It's done for security reasons to protect the system from intruders to prevent them from sending requests that can pull the entire database at a time.
- HTTP Responses:
-
- 200 if artifact_type is valid
- 404 if no Artifact Type is defined to handle specified value of artifact_type
- Response schema: [JSON list with artifacts' metadata]
- Create a new Artifact draft
-
- POST /v2/artifacts/{artifact_type}/{type_version}/creating
- Creates a new artifact record in database, the status of artifact is set to CREATING. Request body may contain initial metadata of the artifact.
- URL parameters:
-
- artifact_type identifier of the artifact type, should be equal to a valid constant defined in one of the active artifact plugins.
- type_version identifier defining the version of artifact type.
- HTTP Responses:
-
- 201 if everything went fine. Location header is set to the artifact location
- 404 if no Artifact Type is defined to handle specified value of artifact_type and/or type_version
- 400 if an artifact of this type with the same name and version already exists.
- Response schema: [JSON with created artifact]
- Publish an Artifact
-
- POST /v2/artifacts/{artifact_type}/{type_version}/{id}/publish
- Publishes an artifact, i.e. moves it to ACTIVE state.
- URL parameters:
-
- artifact_type identifier of the artifact type, should be equal to a valid constant defined in one of the active artifact plugins.
- id identifier of the artifact
- type_version identifier defining the version of artifact type.
- HTTP Responses:
-
- 200 if everything went fine
- 404 if no artifact with the given ID was found or if the type of the found artifact differs from type specified by artifact_type parameter (if it is not equal to generic value 'artifacts') or if the found artifact is not owned by the current tenant.
- 400 if the artifact draft has dependencies on missing or non-published artifacts.
- 403 if the artifact is not in the CREATING state
- Request body: None
- Response schema: [JSON with published artifact]
- Get an artifact
-
- GET /v2/artifacts/{artifact_type}/[{type_version}]/{id}
- Returns an artifact record with all the common and type-specific metadata
- URL parameters:
-
- artifact_type identifier of the artifact type, should be equal to a valid constant defined in one of the active artifact plugins.
- id identifier of the artifact
- type_version optional identifier defining the version of artifact type. Unlike in other (modifying) calls in this one it can be omitted to provide possibility to get the artifact by its type and id regardless of type version.
- HTTP Responses:
-
- 200 if everything went fine
- 404 if no artifact with the given ID was found or if the type of the found artifact differs from type specified by artifact_type parameter (if it is not equal to generic value 'artifacts') or if the found artifact is not accessible by the current tenant.
- Response schema: [JSON artifact definition, TBD]
- Update an Artifact
-
- PATCH /v2/artifacts/{artifact_type}/{type_version}/{id}
- Updates artifact's metadata fields. If the artifact is in state other than CREATING then only mutable fields may be updated.
- URL parameters:
-
- artifact_type identifier of the artifact type, should be equal to a valid constant defined in one of the active artifact plugins.
- id identifier of the artifact
- HTTP Responses:
-
- 200 if everything went fine
- 404 if no artifact with the given ID was found or if the type of the found artifact differs from type specified by artifact_type parameter (if it is not equal to generic value 'artifacts') or if the found artifact is not owned by the current tenant.
- 403 if the PATCH attempts to modify the immutable property while the artifact's state is other than CREATING
- Request schema: [JSON patch, TBD]
- Response schema: [JSON artifact definition, TBD]
- Delete an Artifact
-
DELETE /v2/artifacts/{artifact_type}/{type_version}/{id}
Deletes an artifact. See Deleting an Artifact for details
- URL parameters:
-
- artifact_type identifier of the artifact type, should be equal to a valid constant defined in one of the active artifact plugins. May also contain value equal to "artifacts"
- id identifier of the artifact
- type_version identifier defining the version of artifact type.
HTTP Responses:
- 200 if everything went fine
- 404 if no artifact with the given ID was found or if the type of the
-
found artifact differs from type specified by artifact_type parameter (if it is not equal to generic value 'artifacts') or if the found artifact is not owned by the current tenant.
- 400 if there are other artifacts which depend on the given one.
A detailed example:
Let's assume that the artifact type has several type-specific properties, defined as follows:
tags = Array(item_type=String()) dependencies = ArtifactReferenceList() blob = BinaryObject()
Sample HTTP-requests for the given artifact will be given below.
- GET /v2/artifacts/{artifact_type}/{id}
Retrieves an artifact with type artifact_type and id id.
- PATCH /v2/artifacts/{artifact_type}/{type_version}/{id} body = [{'op': 'add', 'path': '/tags/-', 'value': 'new'}]
This request appends string 'new' to a tags property. Here tags is not a reserved name, like in images, it is just the name chosen for an artifact property representing an array of strings. As this is a data-modifying request, it should include the type_version part of the URI to ensure that caller knows exactly which version of the artifact schema is being targeted.
- PATCH /v2/artifacts/{artifact_type}/{type_version}/{id} body = [{'op': 'remove', 'path': '/dependencies/0'}]
This request removes first element from the artifact's dependencies property. Mind that dependencies is not a reserved word, but a custom property name for a list of ArtifactReferences.
PUT /v2/artifacts/{artifact_type}/{type_version}/{id}/blob or POST /v2/artifacts/{artifact_type}/{type_version}/{id}/blob
content-type 'application/octet-stream' body = SOMEDATA
This request uploads data specified in request's body to BinaryObject property blob.
- GET /v2/artifacts/{artifact_type}/{id}/blob/download
This request retrieves the value of BinaryObject property blob.
- DELETE /v2/artifacts/{artifact_type}/{type_version}/{id}/files/{file_id}
Security impact
- The artifact types (their type-specific metadata fields and BLOB kinds) are defined in independent python modules (plugins). This code may be provided by third-party developers, and thus has to be inspected for potential security problems. However, an explicit cloud operators action is required to enable this modules (i.e. they are not user-supplied), so while the operator enables only the trusted plugins there are no security threats.
- The artifact types may define custom logic to validate the values of some of their type-specific metadata fields. This Custom logic is part of the plugin (i.e. cloud operator's action is required to enable it). Thus there is no security issue here unless the operator enables untrusted plugin.
- As this change adds a set of new APIs, a set of new policies should be added as well to provide a role-based access to these APIs. Plugin-specific policies may be added later. However, this spec does not include any actions for these policies, so they have to be specified by later specs.
Notifications impact
To be added later with different specifications / blueprints
Other end user impact
As new APIs are being added, appropriate changes to python-glanceclient and glance CLI should be made to support this interactions.
Performance Impact
The new APIs and data models should follow the same architecture as the existing ones. Thus there should be now impact on performance when calling the APIs.
Long running tasks (such as artifact deletion) should be made asynchronous and should be executed by dedicated background workers, so they will not interfere with the API performance. The implementation of the asynchronous task should reuse the existing delayed delete functionality.
Other deployer impact
The database schema changes should be made with migrations. This migrations have to be executed prior the usage of the new functionality.
Glance deployment should include adding and activating the plugins which define artifact types.
Developer impact
Existing APIs are not modified.
All the artifact-related actions will be available as new API endpoints under the /v2/ branch
The existing images API will not be migrated to artifacts in v2 branch. After artifacts are implemented and stabilized there will be an alternative implementation of Images which will use artifacts' semantic instead of the current one, however this implementation will not substitute the existing one
Deprecation of the current images API is beyond the scope of the current spec and should not happen unless a separate blueprint is filed and a proper deprecation period is announced.
Implementation
Assignee(s)
- Primary assignee:
-
ativelkov
- Other contributors:
-
gokrokve mfedosin ivasilevskaya
Reviewers
mfedosin jokke hemanth-makkapati nikhil-komawar
Work Items
- The database layer and data migrations for Artifacts and their common metadata properties
- The database layer and data migrations to store and manage the values of type-specific metadata fields and blob references
- The plugin interfaces which will allow to specify artifact types and their metadata structures.
- The REST API for artifact composition, publishing, deletion and search of artifacts, as well as retrival of their data and metadata
- Modifications to plugin interface to allow custom logic definition for importing and exporting artifacts as a single operation
- The REST API to support import/export operations for artifacts
- The database layer and data migrations to add artifact dependency relations
- The REST API to support defining dependency relations during artifact composition
- delayed_delete feature: modifying the current delayed delete to support artifact deletion.
- Modifications to python-glancecleint to make use of all the new APIs.
Dependencies
No new dependencies required.
Testing
All the new APIs should be covered by functional and integration tests with Tempest
Data migrations and database API should be covered by Unit tests.
Documentation Impact
All the new APIs, configuration options and policies should be documented.
A new document - "Plugin developers guide" has to be added.
References
- Initial specification draft with comments <https://docs.google.com/a/mirantis.com/document/d/1tOTsIytVWtXGUaT2Ia4V5PWq 4CiTfZPDn6rpRm5In7U/edit>
- Summit Etherpad from Artifacts' discussion session <http://etherpad.openstack.org/p/juno-hot-artifacts-repository-finalize-desi gn>
- Artifact DB Schema
- API Working group sorting guidelines <https://github.com/openstack/api-wg/blob/master/guidelines/ pagination_filter_sort.rst>