-Convert architecture overview to RST. -Convert basic_environment to RST. -Add associated figures. Change-Id: I5dbc8bd79a4745cd49454000e807c50ec441cee4 Implements: blueprint installguide-liberty
12 KiB
Architecture
Overview
The OpenStack project is an open source cloud computing platform that supports all types of cloud environments. The project aims for simple implementation, massive scalability, and a rich set of features. Cloud computing experts from around the world contribute to the project.
OpenStack provides an Infrastructure-as-a-Service (IaaS) solution through a variety of complemental services. Each service offers an application programming interface (API) that facilitates this integration. The following table provides a list of OpenStack services:
| Service | Project name | Description |
|---|---|---|
| Dashboard | Horizon | Provides a web-based self-service portal to interact with underlying OpenStack services, such as launching an instance, assigning IP addresses and configuring access controls. |
| Compute | Nova | Manages the lifecycle of compute instances in an OpenStack environment. Responsibilities include spawning, scheduling and decommissioning of virtual machines on demand. |
| Networking | Neutron | Enables Network-Connectivity-as-a-Service for other OpenStack services, such as OpenStack Compute. Provides an API for users to define networks and the attachments into them. Has a pluggable architecture that supports many popular networking vendors and technologies. |
| Object Storage | Swift | Stores and retrieves arbitrary unstructured data objects via a RESTful, HTTP based API. It is highly fault tolerant with its data replication and scale-out architecture. Its implementation is not like a file server with mountable directories. In this case, it writes objects and files to multiple drives, ensuring the data is replicated across a server cluster. |
| Block Storage | Cinder | Provides persistent block storage to running instances. Its pluggable driver architecture facilitates the creation and management of block storage devices. |
| Identity service | Keystone | Provides an authentication and authorization service for other OpenStack services. Provides a catalog of endpoints for all OpenStack services. |
| Image service | Glance | Stores and retrieves virtual machine disk images. OpenStack Compute makes use of this during instance provisioning. |
| Telemetry | Ceilometer | Monitors and meters the OpenStack cloud for billing, benchmarking, scalability, and statistical purposes. |
| Orchestration | Heat | Orchestrates multiple composite cloud applications by using either the native HOT template format or the AWS CloudFormation template format, through both an OpenStack-native REST API and a CloudFormation-compatible Query API. |
| Database service | Trove | Provides scalable and reliable Cloud Database-as-a-Service functionality for both relational and non-relational database engines. |
| Data processing service | Sahara | Provides capabilties to provision and scale Hadoop clusters in OpenStack by specifying parameters like Hadoop version, cluster topology and nodes hardware details. |
This guide describes how to deploy these services in a functional test environment and, by example, teaches you how to build a production environment. Realistically, you would use automation tools such as Ansible, Chef, and Puppet to deploy and manage a production environment.
Conceptual architecture
Launching a virtual machine or instance involves many interactions among several services. The following diagram provides the conceptual architecture of a typical OpenStack environment.
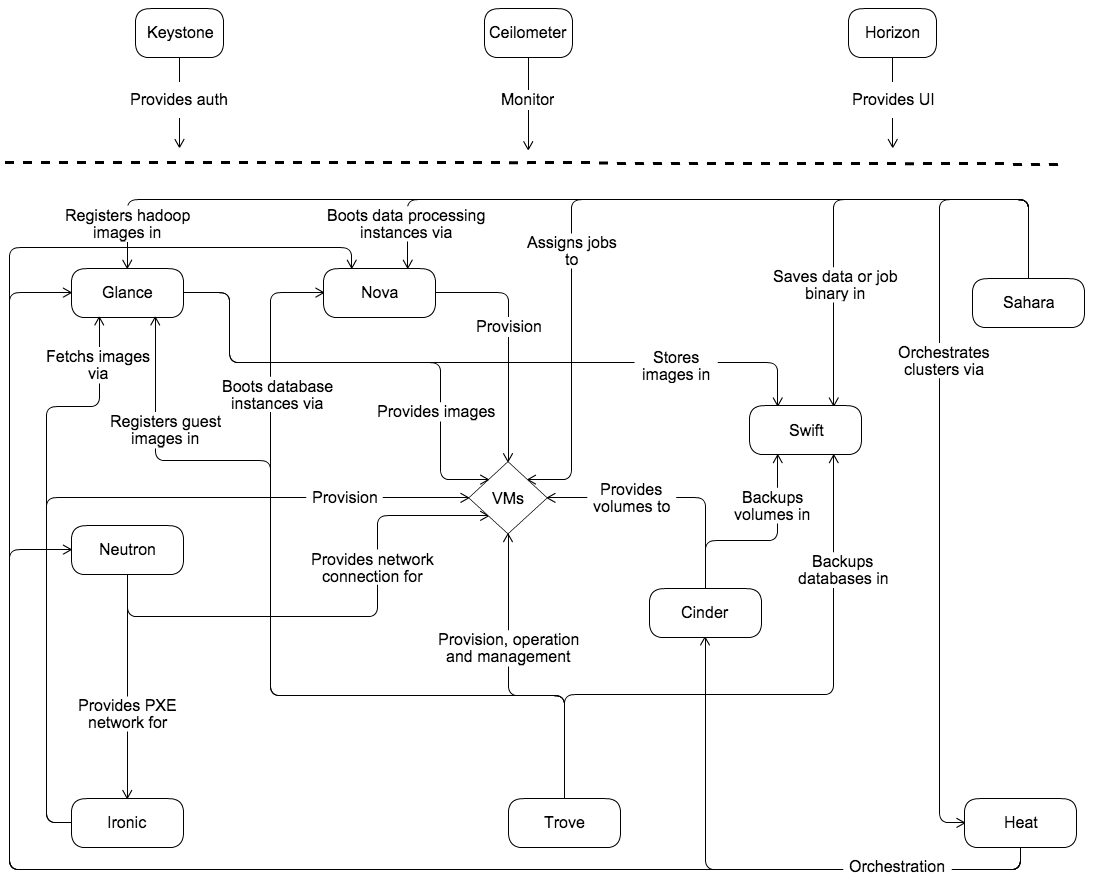
Example architectures
OpenStack is highly configurable to meet different needs with various compute, networking, and storage options. This guide enables you to choose your own OpenStack adventure using a combination of core and optional services. This guide uses the following example architectures:
- Three-node architecture with OpenStack Networking (neutron) and
optional nodes for Block Storage and Object Storage services.
The controller node runs the Identity service, Image Service, management portions of Compute and Networking, Networking plug-in, and the dashboard. It also includes supporting services such as a SQL database, message queue, and Network Time Protocol (NTP).
Optionally, the controller node runs portions of Block Storage, Object Storage, Orchestration, Telemetry, Database, and Data processing services. These components provide additional features for your environment.
The network node runs the Networking plug-in and several agents that provision tenant networks and provide switching, routing, NAT, and DHCP services. This node also handles external (Internet) connectivity for tenant virtual machine instances.
The compute node runs the hypervisor portion of Compute that operates tenant virtual machines or instances. By default, Compute uses KVM as the hypervisor. The compute node also runs the Networking plug-in and an agent that connect tenant networks to instances and provide firewalling (security groups) services. You can run more than one compute node.
Optionally, the compute node runs a Telemetry agent to collect meters. Also, it can contain a third network interface on a separate storage network to improve performance of storage services.
The optional Block Storage node contains the disks that the Block Storage service provisions for tenant virtual machine instances. You can run more than one of these nodes.
Optionally, the Block Storage node runs a Telemetry agent to collect meters. Also, it can contain a second network interface on a separate storage network to improve performance of storage services.
The optional Object Storage nodes contain the disks that the Object Storage service uses for storing accounts, containers, and objects. You can run more than two of these nodes. However, the minimal architecture example requires two nodes.
Optionally, these nodes can contain a second network interface on a separate storage network to improve performance of storage services.
Note
When you implement this architecture, skip <TODO>.



- Two-node architecture with legacy networking (nova-network) and
optional nodes for Block Storage and Object Storage services.
The controller node runs the Identity service, Image service, management portion of Compute, and the dashboard. It also includes supporting services such as a SQL database, message queue, and Network Time Protocol (NTP).
Optionally, the controller node runs portions of Block Storage, Object Storage, Orchestration, Telemetry, Database, and Data processing services. These components provide additional features for your environment.
The compute node runs the hypervisor portion of Compute that operates tenant virtual machines or instances. By default, Compute uses KVM as the hypervisor. Compute also provisions tenant networks and provides firewalling (security groups) services. You can run more than one compute node.
Optionally, the compute node runs a Telemetry agent to collect meters. Also, it can contain a third network interface on a separate storage network to improve performance of storage services.
The optional Block Storage node contains the disks that the Block Storage service provisions for tenant virtual machine instances. You can run more than one of these nodes.
Optionally, the Block Storage node runs a Telemetry agent to collect meters. Also, it can contain a second network interface on a separate storage network to improve performance of storage services.
The optional Object Storage nodes contain the disks that the Object Storage service uses for storing accounts, containers, and objects. You can run more than two of these nodes. However, the minimal architecture example requires two nodes.
Optionally, these nodes can contain a second network interface on a separate storage network to improve performance of storage services.
Note
When you implement this architecture, skip <TODO>


