Updated from https://wiki.openstack.org/wiki/Rally Change-Id: I520b08202910ad476447fa09ca0a5993fc1bffc5
2.7 KiB
What is Rally?
If you are here, you are probably familiar with OpenStack and you also know that it's a really huge ecosystem of cooperative services. When something fails, performs slowly or doesn't scale, it's really hard to answer different questions on "what", "why" and "where" has happened. Another reason why you could be here is that you would like to build an OpenStack CI/CD system that will allow you to improve SLA, performance and stability of OpenStack continuously.
The OpenStack QA team mostly works on CI/CD that ensures that new patches don't break some specific single node installation of OpenStack. On the other hand it's clear that such CI/CD is only an indication and does not cover all cases (e.g. if a cloud works well on a single node installation it doesn't mean that it will continue to do so on a 1k servers installation under high load as well). Rally aims to fix this and help us to answer the question "How does OpenStack work at scale?". To make it possible, we are going to automate and unify all steps that are required for benchmarking OpenStack at scale: multi-node OS deployment, verification, benchmarking & profiling.
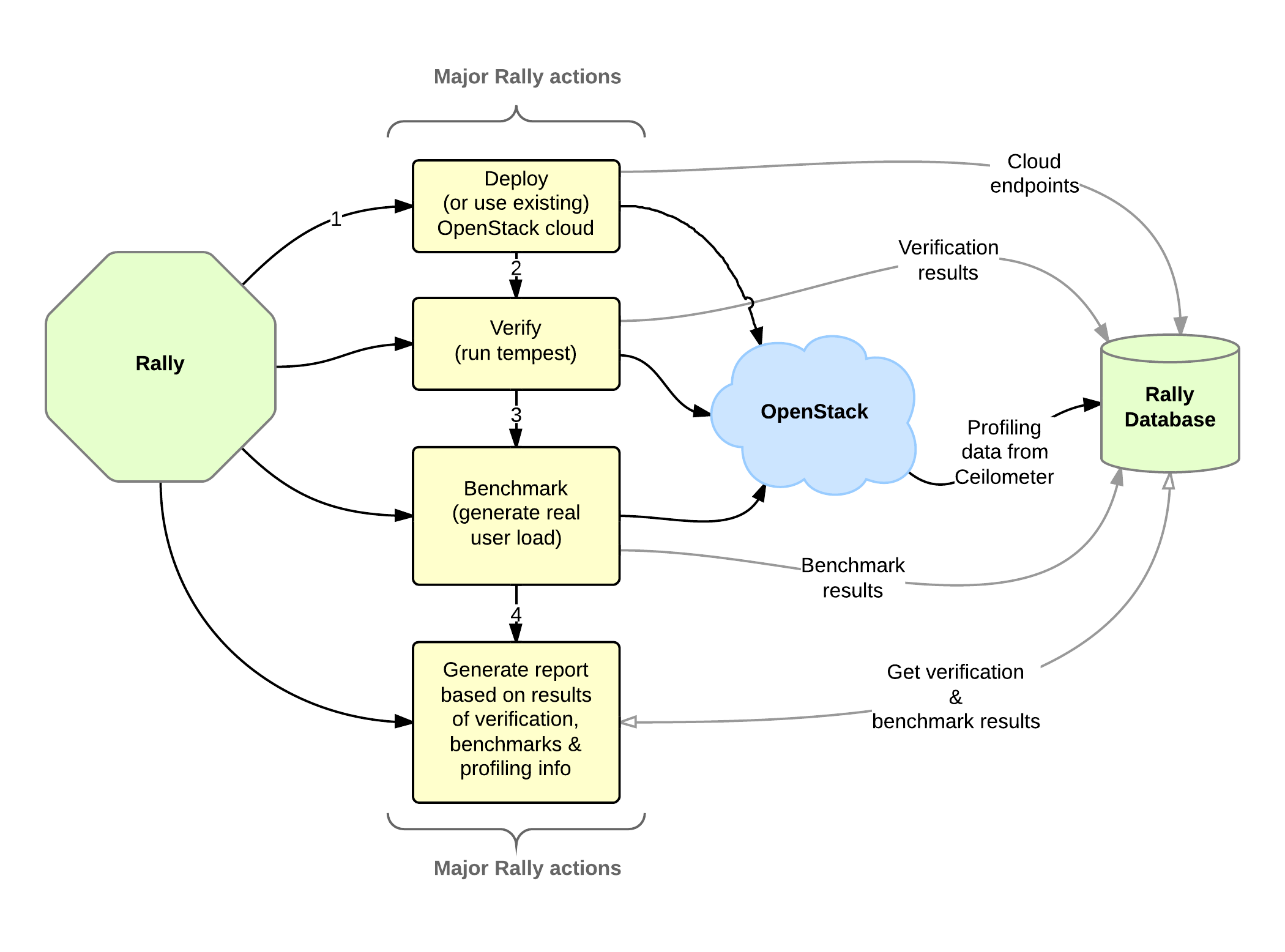
- Deploy engine is not yet another deployer of OpenStack, but just a pluggable mechanism that allows to unify & simplify work with different deployers like: DevStack, Fuel, Anvil on hardware/VMs that you have.
- Verification - (work in progress) uses tempest to verify the functionality of a deployed OpenStack cloud. In future Rally will support other OS verifiers.
- Benchmark engine - allows to create parameterized load on the cloud based on a big repository of benchmarks.
Deeper in Rally:
overview concepts deploy_engines server_providers verify installation usage
Development information:
cmds implementation improve_rally rally_gatejob
Indices and tables
genindexmodindexsearch