Updated from https://wiki.openstack.org/wiki/Rally Change-Id: I520b08202910ad476447fa09ca0a5993fc1bffc5
4.8 KiB
Overview
Use Cases
Before diving deep in Rally architecture let's take a look at 3 major high level Rally Use Cases:
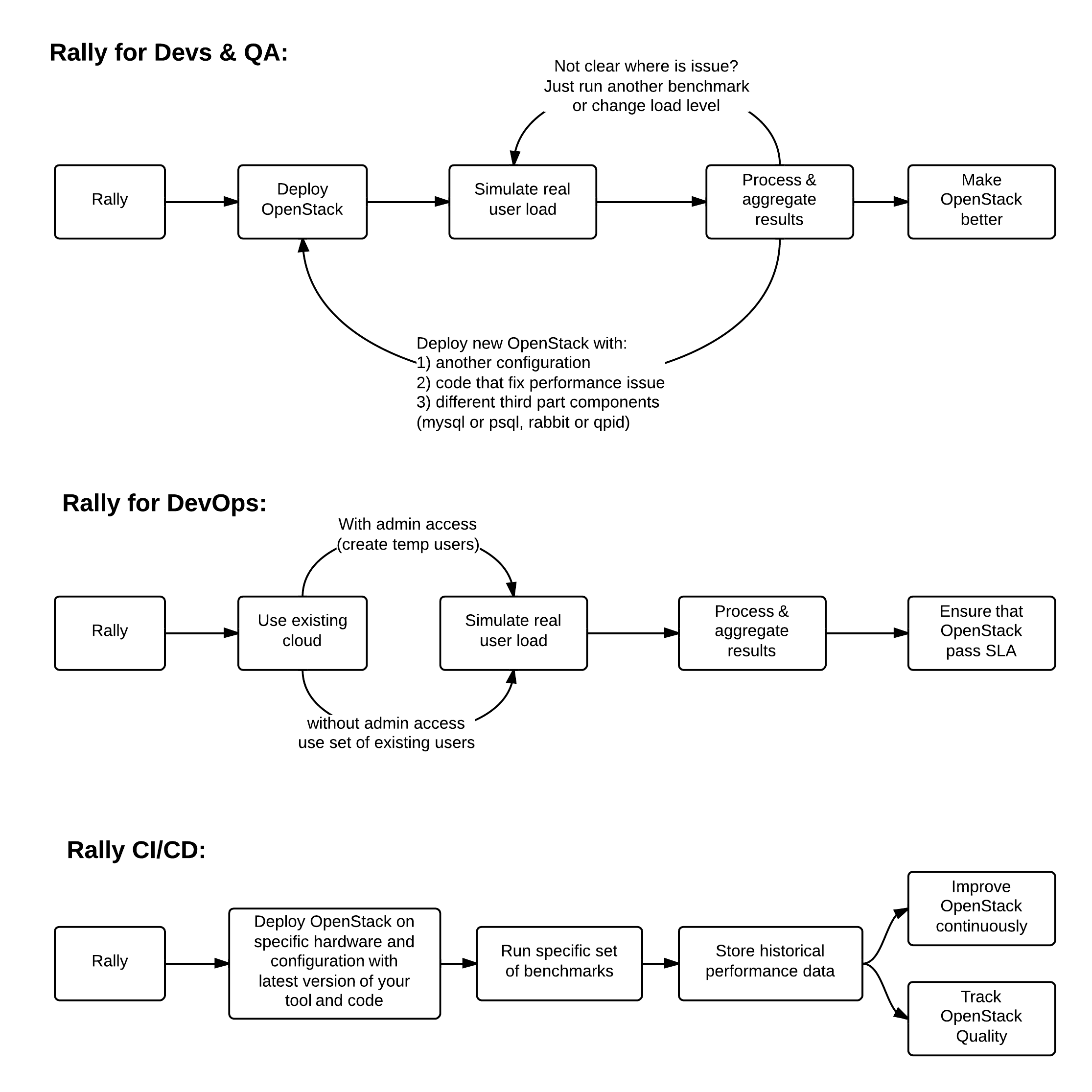
Typical cases where Rally aims to help are:
- Automate measuring & profiling focused on how new code changes affect the OS performance;
- Using Rally profiler to detect scaling & performance issues;
- Investigate how different deployments affect the OS performance:
- Find the set of suitable OpenStack deployment architectures;
- Create deployment specifications for different loads (amount of controllers, swift nodes, etc.);
- Automate the search for hardware best suited for particular OpenStack cloud;
- Automate the production cloud specification generation:
- Determine terminal loads for basic cloud operations: VM start & stop, Block Device create/destroy & various OpenStack API methods;
- Check performance of basic cloud operations in case of different loads.
Architecture
Usually OpenStack projects are as-a-Service, so Rally provides this approach and a CLI driven approach that does not require a daemon:
- Rally as-a-Service: Run rally as a set of daemons that present Web UI (work in progress) so 1 RaaS could be used by whole team.
- Rally as-an-App: Rally as a just lightweight CLI app (without any daemons), that makes it simple to develop & much more portable.
How is this possible? Take a look at diagram below:
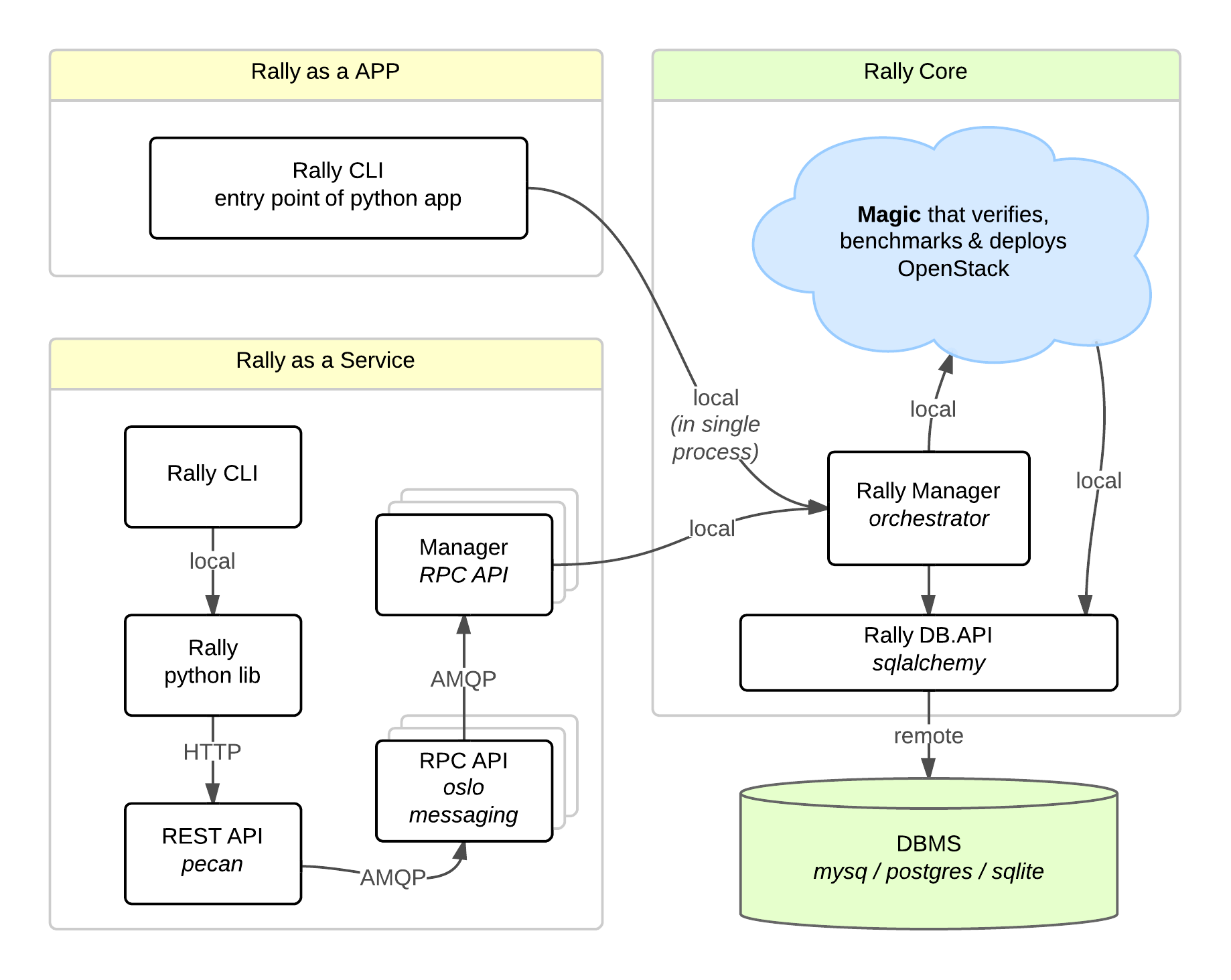
So what is behind Rally?
Rally Components
Rally consists of 4 main components:
- Server Providers - provide servers (virtual servers), with ssh access, in one L3 network.
- Deploy Engines - deploy OpenStack cloud on servers that are presented by Server Providers
- Verification - component that runs tempest (or another pecific set of tests) against a deployed cloud, collects results & presents them in human readable form.
- Benchmark engine - allows to write parameterized benchmark scenarios & run them against the cloud.
But why does Rally need these components? It becomes really clear if we try to imagine: how I will benchmark cloud at Scale, if ...
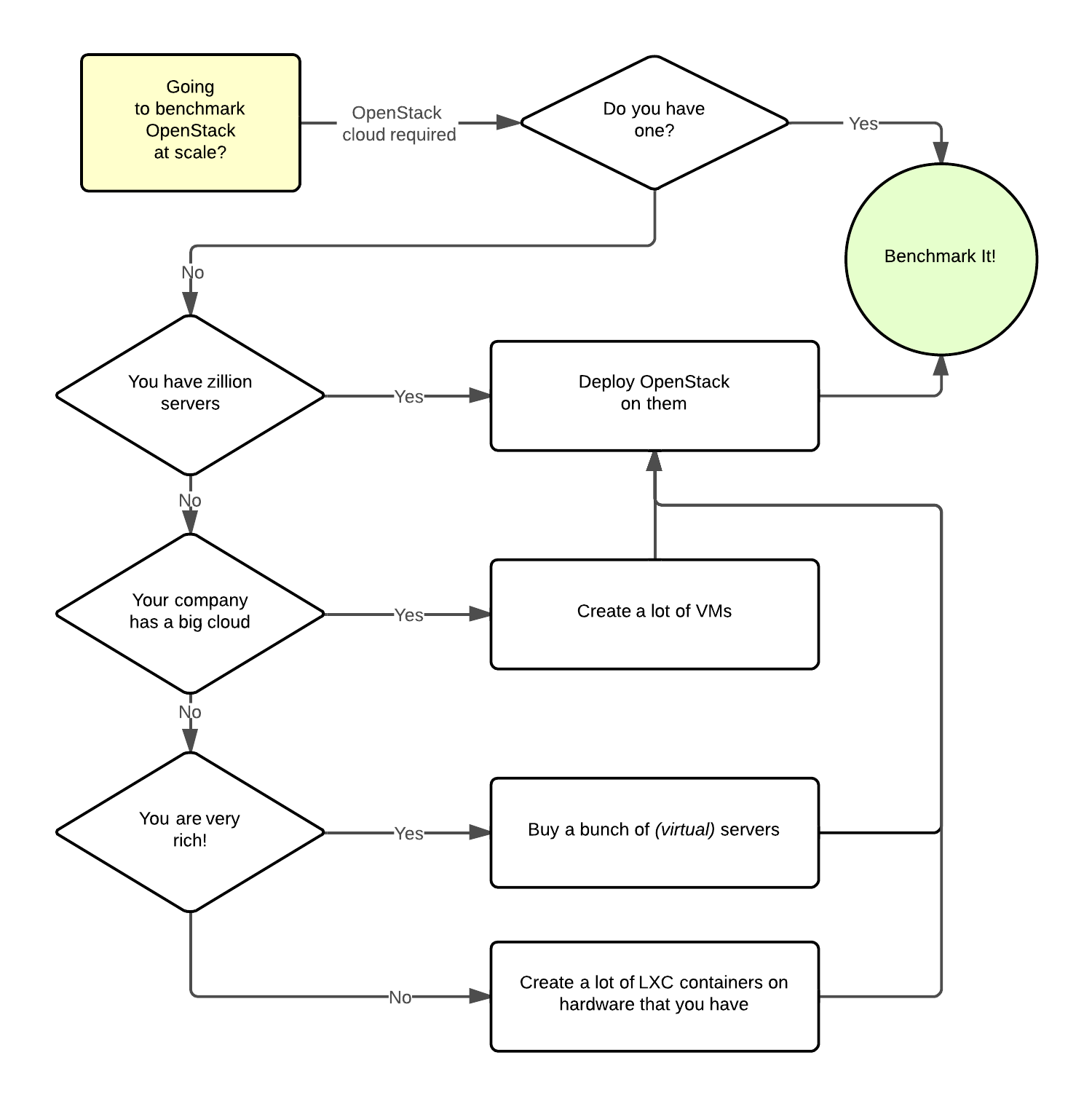
Rally in action
How amqp_rpc_single_reply_queue affects performance
To show Rally's capabilities and potential we used NovaServers.boot_and_destroy scenario to see how amqp_rpc_single_reply_queue option affects VM bootup time. Some time ago it was shown that cloud performance can be boosted by setting it on so naturally we decided to check this result. To make this test we issued requests for booting up and deleting VMs for different number of concurrent users ranging from one to 30 with and without this option set. For each group of users a total number of 200 requests was issued. Averaged time per request is shown below:
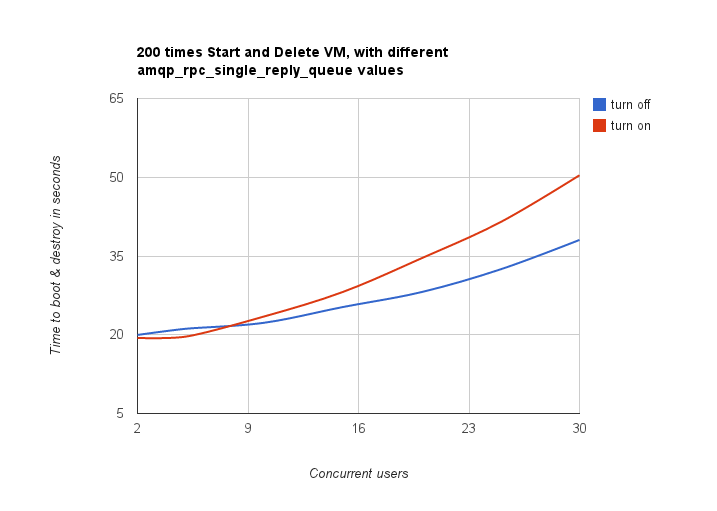
So apparently this option affects cloud performance, but not in the way it was thought before.
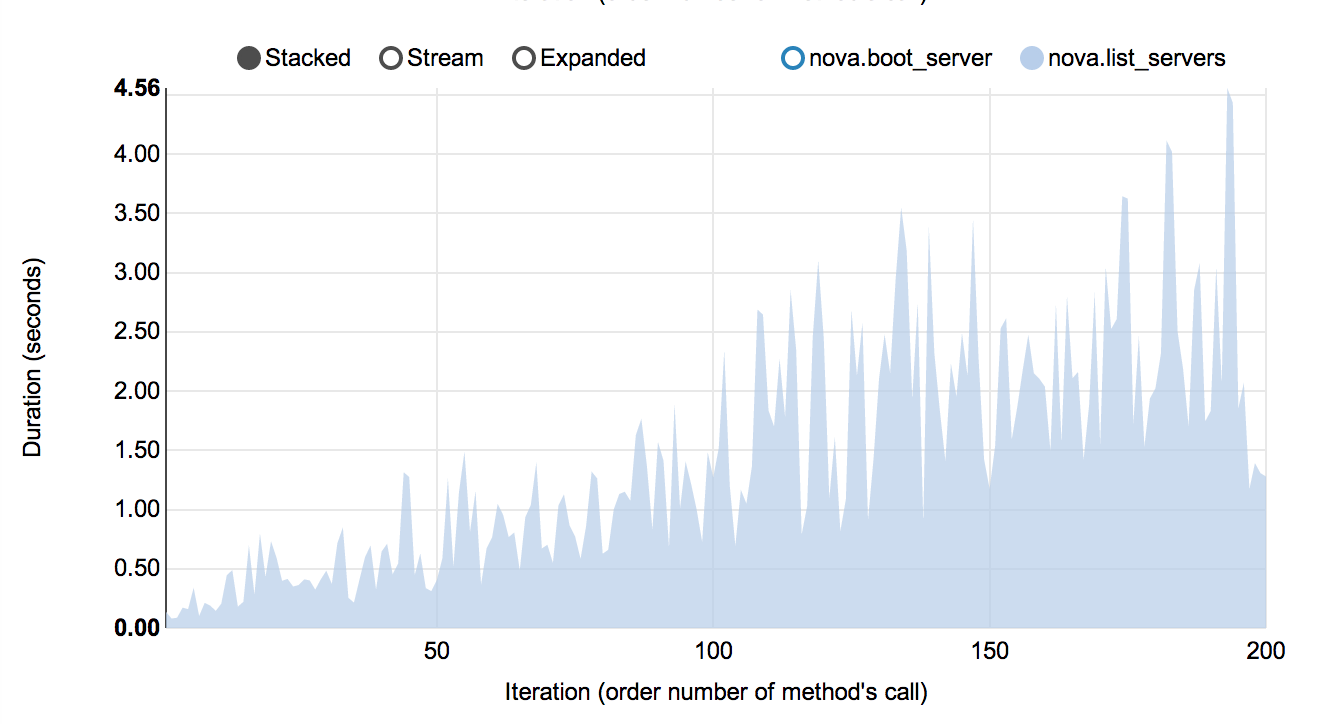
Performance of Nova instance list command
Context: 1 OpenStack user
Scenario: 1) boot VM from this user 2) list VM
Runner: Repeat 200 times.
As a result, on every next iteration user has more and more VMs and performance of VM list is degrading quite fast:
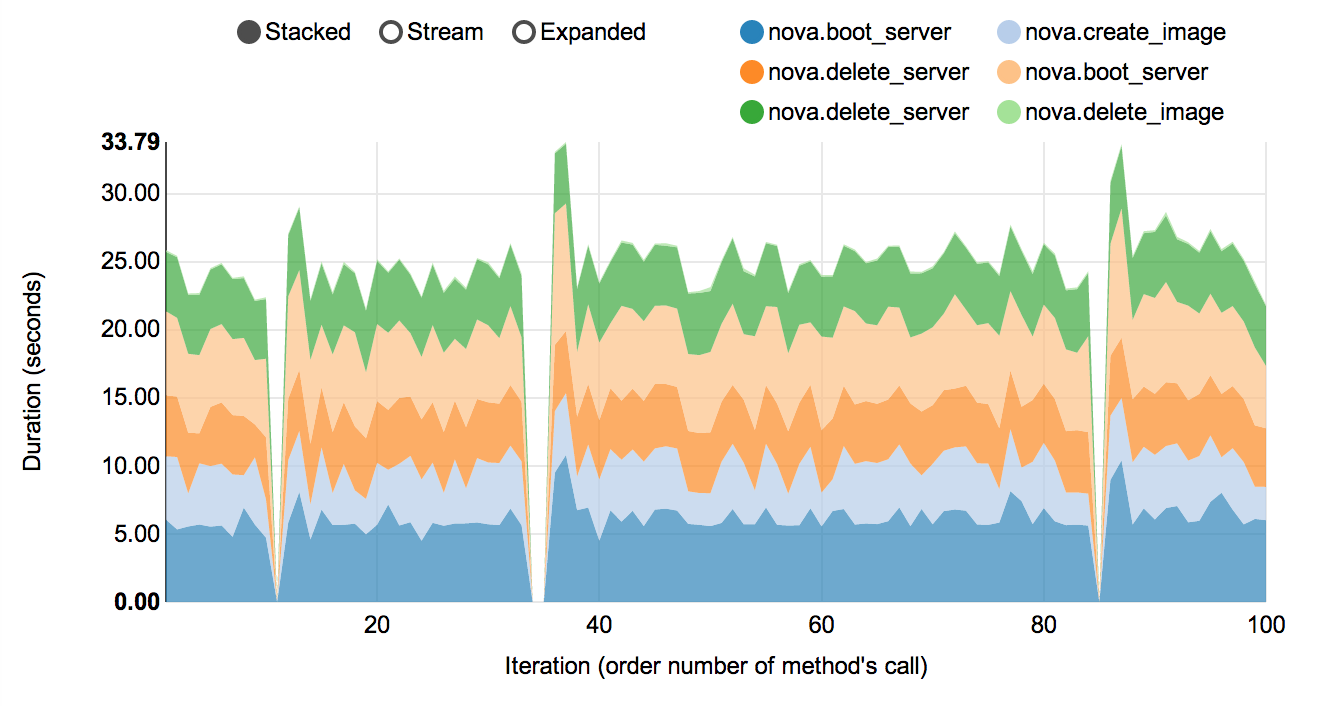
Complex scenarios & detailed information
For example NovaServers.snapshot contains a lot of "atomic" actions:
- boot VM
- snapshot VM
- delete VM
- boot VM from snapshot
- delete VM
- delete snapshot
Fortunately Rally collects information about duration of all these operation for every iteration.
As a result we are generating beautiful graph image:: Rally_snapshot_vm.png