Instead of having code that is some what like the notifier
code we already have, but is duplicated and is slightly different
in the task class just move the code that was in the task class (and
doing similar actions) to instead now use a notifier that is directly
contained in the task base class for internal task triggering of
internal task events.
Breaking change: alters the capabilities of the task to process
notifications itself, most actions now must go through the task
notifier property and instead use that (update_progress still exists
as a common utility method, since it's likely the most common type
of notification that will be used).
Removes the following methods from task base class (as they are
no longer needed with a notifier attribute):
- trigger (replaced with notifier.notify)
- autobind (removed, not replaced, can be created by the user
of taskflow in a simple manner, without requiring
functionality in taskflow)
- bind (replaced with notifier.register)
- unbind (replaced with notifier.unregister)
- listeners_iter (replaced with notifier.listeners_iter)
Due to this change we can now also correctly proxy back events from
remote tasks to the engine for correct proxying back to the original
task.
Fixes bug 1370766
Change-Id: Ic9dfef516d72e6e32e71dda30a1cb3522c9e0be6
14 KiB
Workers
Overview
This is engine that schedules tasks to workers -- separate processes dedicated for certain atoms execution, possibly running on other machines, connected via amqp (or other supported kombu transports).
Note
This engine is under active development and is experimental but it is usable and does work but is missing some features (please check the blueprint page for known issues and plans) that will make it more production ready.
Terminology
- Client
-
Code or program or service that uses this library to define flows and run them via engines.
- Transport + protocol
-
Mechanism (and protocol on top of that mechanism) used to pass information between the client and worker (for example amqp as a transport and a json encoded message format as the protocol).
- Executor
-
Part of the worker-based engine and is used to publish task requests, so these requests can be accepted and processed by remote workers.
- Worker
-
Workers are started on remote hosts and has list of tasks it can perform (on request). Workers accept and process task requests that are published by an executor. Several requests can be processed simultaneously in separate threads. For example, an executor can be passed to the worker and configured to run in as many threads (green or not) as desired.
- Proxy
-
Executors interact with workers via a proxy. The proxy maintains the underlying transport and publishes messages (and invokes callbacks on message reception).
Requirements
- Transparent: it should work as ad-hoc replacement for existing (local) engines with minimal, if any refactoring (e.g. it should be possible to run the same flows on it without changing client code if everything is set up and configured properly).
- Transport-agnostic: the means of transport should be abstracted so that we can use oslo.messaging, gearmand, amqp, zookeeper, marconi, websockets or anything else that allows for passing information between a client and a worker.
- Simple: it should be simple to write and deploy.
- Non-uniformity: it should support non-uniform workers which allows different workers to execute different sets of atoms depending on the workers published capabilities.
Use-cases
- Glance
- Image tasks (long-running)
- Convert, import/export & more...
- Image tasks (long-running)
- Heat
- Engine work distribution
- Rally
- Load generation
- Your use-case here
Design
There are two communication sides, the executor and worker that communicate using a proxy component. The proxy is designed to accept/publish messages from/into a named exchange.
High level architecture
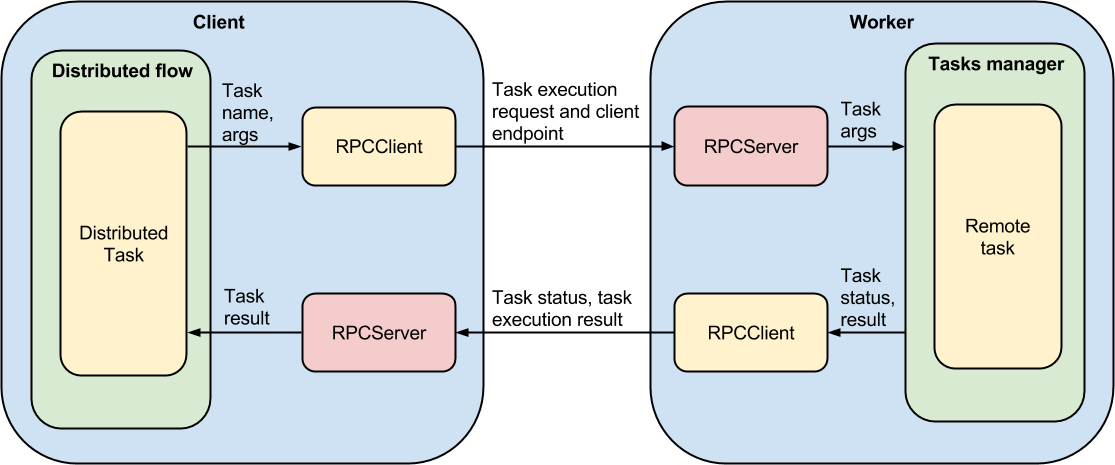
Executor and worker communication
Let's consider how communication between an executor and a worker happens. First of all an engine resolves all atoms dependencies and schedules atoms that can be performed at the moment. This uses the same scheduling and dependency resolution logic that is used for every other engine type. Then the atoms which can be executed immediately (ones that are dependent on outputs of other tasks will be executed when that output is ready) are executed by the worker-based engine executor in the following manner:
- The executor initiates task execution/reversion using a proxy object.
- :py
~taskflow.engines.worker_based.proxy.Proxypublishes task request (format is described below) into a named exchange using a routing key that is used to deliver request to particular workers topic. The executor then waits for the task requests to be accepted and confirmed by workers. If the executor doesn't get a task confirmation from workers within the given timeout the task is considered as timed-out and a timeout exception is raised. - A worker receives a request message and starts a new thread for
processing it.
- The worker dispatches the request (gets desired endpoint that actually executes the task).
- If dispatched succeeded then the worker sends a confirmation
response to the executor otherwise the worker sends a failed response
along with a serialized :py
failure <taskflow.types.failure.Failure>object that contains what has failed (and why). - The worker executes the task and once it is finished sends the result back to the originating executor (every time a task progress event is triggered it sends progress notification to the executor where it is handled by the engine, dispatching to listeners and so-on).
- The executor gets the task request confirmation from the worker and
the task request state changes from the
PENDINGto theRUNNINGstate. Once a task request is in theRUNNINGstate it can't be timed-out (considering that task execution process may take unpredictable time). - The executor gets the task execution result from the worker and passes it back to the executor and worker-based engine to finish task processing (this repeats for subsequent tasks).
Note
:py~taskflow.types.failure.Failure objects are not
directly json-serializable (they contain references to tracebacks which
are not serializable), so they are converted to dicts before sending and
converted from dicts after receiving on both executor & worker sides
(this translation is lossy since the traceback won't be fully
retained).
Executor execute format
- task_name - full task name to be performed
- task_cls - full task class name to be performed
- action - task action to be performed (e.g. execute, revert)
- arguments - arguments the task action to be called with
- result - task execution result (result or :py
~taskflow.types.failure.Failure) [passed to revert only]
Additionally, the following parameters are added to the request message:
- reply_to - executor named exchange workers will send responses back to
- correlation_id - executor request id (since there can be multiple request being processed simultaneously)
Example:
{
"action": "execute",
"arguments": {
"x": 111
},
"task_cls": "taskflow.tests.utils.TaskOneArgOneReturn",
"task_name": "taskflow.tests.utils.TaskOneArgOneReturn",
"task_version": [
1,
0
]
}Worker response format
When running:
{
"data": {},
"state": "RUNNING"
}When progressing:
{
"details": {
"progress": 0.5
},
"event_type": "update_progress",
"state": "EVENT"
}When succeeded:
{
"data": {
"result": 666
},
"state": "SUCCESS"
}When failed:
{
"data": {
"result": {
"exc_type_names": [
"RuntimeError",
"StandardError",
"Exception"
],
"exception_str": "Woot!",
"traceback_str": " File \"/homes/harlowja/dev/os/taskflow/taskflow/engines/action_engine/executor.py\", line 56, in _execute_task\n result = task.execute(**arguments)\n File \"/homes/harlowja/dev/os/taskflow/taskflow/tests/utils.py\", line 165, in execute\n raise RuntimeError('Woot!')\n",
"version": 1
}
},
"state": "FAILURE"
}Executor revert format
When reverting:
{
"action": "revert",
"arguments": {},
"failures": {
"taskflow.tests.utils.TaskWithFailure": {
"exc_type_names": [
"RuntimeError",
"StandardError",
"Exception"
],
"exception_str": "Woot!",
"traceback_str": " File \"/homes/harlowja/dev/os/taskflow/taskflow/engines/action_engine/executor.py\", line 56, in _execute_task\n result = task.execute(**arguments)\n File \"/homes/harlowja/dev/os/taskflow/taskflow/tests/utils.py\", line 165, in execute\n raise RuntimeError('Woot!')\n",
"version": 1
}
},
"result": [
"failure",
{
"exc_type_names": [
"RuntimeError",
"StandardError",
"Exception"
],
"exception_str": "Woot!",
"traceback_str": " File \"/homes/harlowja/dev/os/taskflow/taskflow/engines/action_engine/executor.py\", line 56, in _execute_task\n result = task.execute(**arguments)\n File \"/homes/harlowja/dev/os/taskflow/taskflow/tests/utils.py\", line 165, in execute\n raise RuntimeError('Woot!')\n",
"version": 1
}
],
"task_cls": "taskflow.tests.utils.TaskWithFailure",
"task_name": "taskflow.tests.utils.TaskWithFailure",
"task_version": [
1,
0
]
}Usage
Workers
To use the worker based engine a set of workers must first be established on remote machines. These workers must be provided a list of task objects, task names, modules names (or entrypoints that can be examined for valid tasks) they can respond to (this is done so that arbitrary code execution is not possible).
For complete parameters and object usage please visit :py~taskflow.engines.worker_based.worker.Worker.
Example:
from taskflow.engines.worker_based import worker as w
config = {
'url': 'amqp://guest:guest@localhost:5672//',
'exchange': 'test-exchange',
'topic': 'test-tasks',
'tasks': ['tasks:TestTask1', 'tasks:TestTask2'],
}
worker = w.Worker(**config)
worker.run()Engines
To use the worker based engine a flow must be constructed (which contains tasks that are visible on remote machines) and the specific worker based engine entrypoint must be selected. Certain configuration options must also be provided so that the transport backend can be configured and initialized correctly. Otherwise the usage should be mostly transparent (and is nearly identical to using any other engine type).
For complete parameters and object usage please see :py~taskflow.engines.worker_based.engine.WorkerBasedActionEngine.
Example with amqp transport:
flow = lf.Flow('simple-linear').add(...)
eng = taskflow.engines.load(flow, engine='worker-based',
url='amqp://guest:guest@localhost:5672//',
exchange='test-exchange',
topics=['topic1', 'topic2'])
eng.run()Example with filesystem transport:
flow = lf.Flow('simple-linear').add(...)
eng = taskflow.engines.load(flow, engine='worker-based',
exchange='test-exchange',
topics=['topic1', 'topic2'],
transport='filesystem',
transport_options={
'data_folder_in': '/tmp/in',
'data_folder_out': '/tmp/out',
})
eng.run()Additional supported keyword arguments:
executor: a class that provides a :py~taskflow.engines.worker_based.executor.WorkerTaskExecutorinterface; it will be used for executing, reverting and waiting for remote tasks.
Limitations
- Atoms inside a flow must receive and accept parameters only from the
ways defined in
persistence <persistence>. In other words, the task that is created when a workflow is constructed will not be the same task that is executed on a remote worker (and any internal state not passed via theinput and output <inputs_and_outputs>mechanism can not be transferred). This means resource objects (database handles, file descriptors, sockets, ...) can not be directly sent across to remote workers (instead the configuration that defines how to fetch/create these objects must be instead). - Worker-based engines will in the future be able to run lightweight tasks locally to avoid transport overhead for very simple tasks (currently it will run even lightweight tasks remotely, which may be non-performant).
- Fault detection, currently when a worker acknowledges a task the engine will wait for the task result indefinitely (a task could take a very long time to finish). In the future there needs to be a way to limit the duration of a remote workers execution (and track there liveness) and possibly spawn the task on a secondary worker if a timeout is reached (aka the first worker has died or has stopped responding).
Interfaces
taskflow.engines.worker_based.worker
taskflow.engines.worker_based.engine
taskflow.engines.worker_based.proxy
taskflow.engines.worker_based.executor